Google for Developers Blog - News about Web, Mobile, AI and Cloud
|
16th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Achieving privacy compliance with your CI/CD: A guide for compliance teams | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks

In the fast-paced world of software development, Continuous Integration and Continuous Deployment (CI/CD) have become cornerstones, enabling teams to deliver high-quality software faster than ever. However, the rise of rapid innovation, increasing use of third-party libraries, and AI-generated code have accelerated vulnerabilities and risks. Therefore, addressing these issues early in the development lifecycle is essential so that teams can launch their products quickly and confidently. The introduction of Checks privacy compliance CI/CD tooling feature represents a significant stride towards addressing these concerns, by reducing manual intervention and automating compliance and privacy standards as part of a release cycle. In this post, we explore the meaning of CI/CD for compliance team members unfamiliar with this technology and how Checks can weave privacy and compliance protection practices into that pipeline. What is CI/CD?Continuous Integration (CI) and Continuous Deployment (CD) are foundational practices in modern software development. They enable development teams to increase efficiency, improve quality, and accelerate delivery. Continuous Integration (CI) automatically integrates code changes from multiple contributors into a software project. This practice enables teams to detect problems early by running automated tests on each change before it is merged into the main branch.
Continuous Deployment (CD) takes automation further by automatically deploying all code changes to a testing or production environment after the build stage. This means that, in addition to automated testing, automated release processes ensure that new changes are accessible to users as quickly as possible. Shifting issue-spotting left with CI/CD pipelinesThe automation of CI/CD processes is typically called “pipelines.” CI/CD pipelines automate the steps software changes go through, from development to deployment. These steps include compiling code, running tests (unit tests, integration tests, etc.), security scans, and more. If all automated tests pass, the changes go live without human intervention in a specific environment, such as testing or production. These pipelines are designed to catch issues as early as possible, embodying the practice known as “shifting left.” The benefits of “shifting left”, particularly when applied through CI/CD pipelines, include:
Checks brings privacy and compliance tests to your CI/CDChecks CI/CD tooling seamlessly integrates app compliance scanning into CI/CD pipelines via plugins for GitHub, Jenkins, and FastLane. You can also use Checks in any other CI/CD system that supports custom scripts, such as GitLab, TeamCity, Bitbucket, and more.
When Checks scans an app, the binary undergoes dynamic and static analysis to understand your data collection and sharing practices, including app dependencies such as SDKs, permissions, and endpoints. This data is then tested against global regulatory requirements, store policies, your custom Checks policies, and your privacy policy to find potential issues and opportunities for improvement. Top 5 benefits of integrating Checks into your CI/CD
By adding Checks as a step in your CI/CD pipeline, you can automate app and code compliance scanning as part of the development lifecycle. The top 5 benefits of integrating Checks in your CI/CD are:
Next stepsGetting started is simple. Start by first signing up for Checks and then adding Checks to your CI/CD pipelines with these simple configuration steps. Once configured, Checks is ready to perform a variety of privacy and compliance verifications. This proactive approach to privacy and compliance safeguards against potential risks and aligns with regulatory compliance requirements, making it an invaluable asset for any compliance and development team.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
9th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Gemini 1.5 Pro Now Available in 180+ Countries; With Native Audio Understanding, System Instructions, JSON Mode and More | ||||||||||||||||||||||||||||||||||||||||||||||||
|
Posted by Jaclyn Konzelmann and Megan Li - Google Labs Grab an API key in Google AI Studio, and get started with the Gemini API Cookbook Less than two months ago, we made our next-generation Gemini 1.5 Pro model available in Google AI Studio for developers to try out. We’ve been amazed by what the community has been able to debug, create and learn using our groundbreaking 1 million context window. Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio (speech) understanding capability and a new File API to make it easy to handle files. We’re also launching new features like system instructions and JSON mode to give developers more control over the model’s output. Lastly, we’re releasing our next generation text embedding model that outperforms comparable models. Go to Google AI Studio to create or access your API key, and start building. Unlock new use cases with audio and video modalitiesWe’re expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
Gemini API ImprovementsToday, we’re addressing a number of top developer requests:
A new embedding model with improved performanceStarting today, developers will be able to access our next generation text embedding model via the Gemini API. The new model, text-embedding-004, (text-embedding-preview-0409 in Vertex AI), achieves a stronger retrieval performance and outperforms existing models with comparable dimensions, on the MTEB benchmarks.
These are just the first of many improvements coming to the Gemini API and Google AI Studio in the next few weeks. We’re continuing to work on making Google AI Studio and the Gemini API the easiest way to build with Gemini. Get started today in Google AI Studio with Gemini 1.5 Pro, explore code examples and quickstarts in our new Gemini API Cookbook, and join our community channel on Discord.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
15th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Meet the inaugural cohort of our Google for Startups Accelerator: AI First North America | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA

Startups are at the forefront of developing solutions for some of humanity's most pressing challenges by using AI, driving breakthroughs across industries from healthcare to cybersecurity. To help AI-focused startups scale quickly while building responsibly, we’re thrilled to introduce the inaugural class of the Google for Startups Accelerator: AI-First program in North America. This new program is for startups building AI solutions based in the U.S. and Canada. This is the first of several AI-focused programs we'll offer throughout the year in Europe, India and Brazil. This equity-free program provides 10 weeks of hands-on mentorship and technical project support to startups using AI in their core service or product. Selected startups will collaborate with a cohort of top peer founders and engage with leaders across Google. The curriculum will give founders access to the latest AI tools (including Google’s own Gemini), and will also include workshops on tech and infrastructure, UX and product, growth, sales, leadership and OKRs. Meet the inaugural class of Google for Startups Accelerator: AI-First, North AmericaWe’re thrilled to introduce the 15 AI startups selected for this accelerator: Aptori, San Jose, CA. Aptori assists developers and security engineers to build secure, high-quality software. Augmend, Seattle, WA. Augmend is an AI native Loom made for developers, making it possible to share expertise, not just videos. Backpack Healthcare, Elkridge, MA. Backpack Healthcare is a pediatric mental health company utilizing proprietary AI technology, an engagement platform, and live therapists to offer personalized care to patients. BrainLogic AI, Menlo Park, CA. BrainLogic AI has built a localized AI agent that connects users and businesses through whatsapp. Cicerai, The Woodlands, TX. Cicerai is an AI-native Legal Practice Management Platform, boosting productivity and enhancing quality. CLIKA, San Jose, CA. CLIKA simplifies deploying AI models on diverse hardware by offering automated model compression and format compilation. Easel AI, Inc., Los Angeles, CA. Easel AI is an AI avatar-based social chat app that runs on iMessage. Findly, San Francisco, CA. Findly is a data visualization integrator using a natural language chat interface. Glass Health, San Francisco, CA. Glass Health empowers clinicians with the best-in-class AI platform for clinical decision support. Kodif, Sunnyvale, CA. Kodif is a low-code AI-powered automation platform for support agent workflows to resolve customer issues. Liminal, Indianapolis, IN. Liminal empowers regulated enterprises to securely deploy and use generative AI, horizontally covering every interaction and use case. Mbue, Austin, TX. Mbue leverages AI to instantly review architectural drawings, catching errors earlier and streamlining the process. Modulo Bio, San Diego, CA. Modulo Bio is building a platform to discover therapeutics that prevent or reverse neurodegenerative diseases. Rocket Doctor, Toronto, ON, Canada. Rocket Doctor is a digital health platform and marketplace that intelligently matches patients and clinicians in a telemedicine 2.0 approach. Sibli, Montreal, QC, Canada. Sibli is a fintech platform that processes unstructured data and identifies key insights for financial analysts. The program kicks off at Cloud Next 2024 and culminates with a high profile Demo Day in June for potential partners, customers and investors. After graduation, startups join the dynamic Google for Startups accelerator community, where they receive ongoing support and have the opportunity to build lasting connections with like-minded founders, mentors and investors. We are honored to partner with this cohort of companies through this accelerator and beyond, to advance their AI technologies. Register your interest to get updates on the program, and join us in celebrating these exceptional startups!
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
12th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Gemma Family Expands with Models Tailored for Developers and Researchers | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager

In February we announced Gemma, our family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. The community's incredible response – including impressive fine-tuned variants, Kaggle notebooks, integration into tools and services, recipes for RAG using databases like MongoDB, and lots more – has been truly inspiring. Today, we're excited to announce our first round of additions to the Gemma family, expanding the possibilities for ML developers to innovate responsibly: CodeGemma for code completion and generation tasks as well as instruction following, and RecurrentGemma, an efficiency-optimized architecture for research experimentation. Plus, we're sharing some updates to Gemma and our terms aimed at improvements based on invaluable feedback we've heard from the community and our partners. Introducing the first two Gemma variantsCodeGemma: Code completion, generation, and chat for developers and businessesHarnessing the foundation of our Gemma models, CodeGemma brings powerful yet lightweight coding capabilities to the community. CodeGemma models are available as a 7B pretrained variant that specializes in code completion and code generation tasks, a 7B instruction-tuned variant for code chat and instruction-following, and a 2B pretrained variant for fast code completion that fits on your local computer. CodeGemma models have several advantages:
Learn more about CodeGemma in our report or try it in this quickstart guide. RecurrentGemma: Efficient, faster inference at higher batch sizes for researchersRecurrentGemma is a technically distinct model that leverages recurrent neural networks and local attention to improve memory efficiency. While achieving similar benchmark score performance to the Gemma 2B model, RecurrentGemma's unique architecture results in several advantages:
To understand the underlying technology, check out our paper. For practical exploration, try the notebook, which demonstrates how to finetune the model. Built upon Gemma foundations, expanding capabilitiesGuided by the same principles of the original Gemma models, the new model variants offer:
Gemma 1.1 updateAlongside the new model variants, we're releasing Gemma 1.1, which includes performance improvements. Additionally, we've listened to developer feedback, fixed bugs, and updated our terms to provide more flexibility. Get started todayThese first Gemma model variants are available in various places worldwide, starting today on Kaggle, Hugging Face, and Vertex AI Model Garden. Here's how to get started:
We invite you to try the CodeGemma and RecurrentGemma models and share your feedback on Kaggle. Together, let's shape the future of AI-powered content creation and understanding.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
8th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| ML Olympiad 2024: Globally Distributed ML Competitions by Google ML Community | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Bitnoori Keum – DevRel Community Manager

The ML Olympiad consists of Kaggle Community Competitions organized by ML GDE, TFUG, and other ML communities, aiming to provide developers with opportunities to learn and practice machine learning. Following successful rounds in 2022 and 2023, the third round has now launched with support from Google for Developers for each competition host. Over the last two rounds, 605 teams participated in 32 competitions, generating 105 discussions and 170 notebooks. We encourage you to join this round to gain hands-on experience with machine learning and tackle real-world challenges. ML Olympiad Community CompetitionsOver 20 ML Olympiad community competitions are currently open. Visit the ML Olympiad page to participate. Smoking Detection in PatientsPredict smoking status with bio-signal ML models
Host: Rishiraj Acharya (AI/ML GDE) / TFUG Kolkata TurtleVision ChallengeDevelop a classification model to distinguish between jellyfish and plastic pollution in ocean imagery
Host: Anas Lahdhiri / MLAct Detect hallucinations in LLMsDetect which answers provided by a Mistral 7B instruct model are most likely hallucinations
Host: Luca Massaron (AI/ML GDE) ZeroWasteEatsFind ML solutions to reduce food wastage
Host: Anushka Raj / TFUG Hajipur Predicting WellnessPredict the percentage of body fat in men using multiple regression methods
Host: Ankit Kumar Verma / TFUG Prayagraj Offbeats EditionBuild a regression model to predict the age of the crab
Host: Ayush Morbar / Offbeats Byte Labs Nashik WeatherPredict the condition of weather in Nashik, India
Host: TFUG Nashik Predicting Earthquake DamagePredict the level of damage to buildings caused by earthquake based on aspects of building location and construction
Host: Usha Rengaraju Forecasting Bangladesh's WeatherPredict the rainy day; amount of rainfall, and average temperature for a particular day.
Host: TFUG Bangladesh (Dhaka) CO2 Emissions Prediction ChallengePredict CO2 emissions per capita for 2030 using global development indicators
Host: Md Shahriar Azad Evan, Shuvro Pal / TFUG North Bengal AI & ML MalaysiaPredict loan approval status
Host: Kuan Hoong (AI/ML GDE) / Artificial Intelligence & Machine Learning Malaysia User Group Sustainable Urban LivingPredict the habitability score of properties
Host: Ashwin Raj / BeyondML Toxic Language (PTBR) Detection(in local language)
Classify Brazilian Portuguese tweets in one of the two classes: toxics or non toxics.
Host: Mikaeri Ohana, Pedro Gengo, Vinicius F. Caridá (AI/ML GDE) Improving disaster responsePredict the humanitarian aid contributions as a response to disasters occurs in the world
Host: Yara Armel Desire / TFUG Abidjan Urban Traffic DensityDevelop predictive models to estimate the traffic density in urban areas
Host: Kartikey Rawat / TFUG Durg Know Your Customer OpinionClassify each customer opinion into several Likert scale
Host: TFUG Surabaya Forecasting India's WeatherPredict the temperature of the particular month
Host: Bilal Aamer & Mohammed Moinuddin / TFUG Hyderabad Classification ChampDevelop classification models to predict tumor malignancy
Host: TFUG Bhopal AI-Powered Job Description GeneratorBuild a system that employs Generative AI and a chatbot interface to automatically generate job descriptions
Host: Akaash Tripathi / TFUG Ghaziabad Machine Translation French-WolofDevelop robust algorithms or models capable of accurately translating French sentences into Wolof.
Host: GalsenAI Water Mapping using Satellite ImageryWater mapping using satellite imagery and deep learning for dam drought detection
Host: Taha Bouhsine / ML Nomads Navigating ML OlympiadTo see all the community competitions around the ML Olympiad, search "ML Olympiad" on Kaggle and look for further related posts on social media using #MLOlympiad. Browse through the available competitions and participate in those that interest you!
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
25th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| #WeArePlay | Meet the founders changing women's lives: Women’s History Month Stories | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Leticia Lago – Developer Marketing

In celebration of Women’s History month, we’re celebrating the founders behind groundbreaking apps and games from around the world - made by women or for women. Let's discover four of my favorites in this latest batch of nine #WeArePlay stories. Múkami Kinoti KimothoRoyelles Revolution / Royelles Revolution: Gaming For Girls (USA)  Múkami's journey began when she noticed the lack of representation for girls in the gaming industry. Determined to change this narrative, she created Royelles, a game designed to inspire girls and non-binary people to pursue careers in STEAM (science, technology, engineering, art, math) fields. The game is anchored in fierce female avatars like the real life NASA scientist Mara who voices a character. Royelles is revolutionizing the gaming landscape and empowering the next generation of innovators. Múkami's excited to release more gamified stories and learning modules, and a range of extended reality and AI-powered avatars based on the game’s characters. "If we're going to effectively educate Gen Z and Gen Alpha, we have to meet them in the metaverse and leverage gamified play as a means of driving education, awareness, inspiration and empowerment.” Leonika Sari Njoto BoedioetomoReblood: Blood Services App (Indonesia)  When her university friend needed an urgent blood transfusion but discovered there was none available in the blood bank, Leonika became aware of the blood donation shortage in Indonesia. Her mission to address this led her to create Reblood, an app connecting blood donors with those in need. With over 140,000 blood donations facilitated to date, Reblood is not only saving lives but also promoting healthier lifestyles with a recently added feature that allows people to find the most affordable medical checkups. “Our goal is to save more lives by raising awareness of blood donation in Indonesia and promoting healthier lifestyles for blood donors.” Luciane Antunes dos Santos and Renato Hélio RauberCARSUL / Car Sul: Urban Mobility App (Brazil)  Luciane was devastated when she lost her son in a car accident. Her and her husband Renato's loss led them to develop Carsul, an urban mobility app prioritizing safety and security. By providing safe transportation options and partnering with government health programs to chauffeur patients long distances to larger hospitals, Carsul is not only preventing accidents but also saving lives. Luciane and Renato's dedication to protecting others from the pain they've experienced is ongoing and they plan to expand to more cities in Brazil. “Carsul was born from this story of loss, inspiring me to protect other lives. Redefining myself in this way is very rewarding.” Diariata (Diata) N'DiayeResonantes / App-Elles: Safety App for Women (France)  After hearing the stories of young people who had experienced abuse that was similar to her own, Spoken word artist Diata developed App-Elles – an app that allows women to send alerts when they're in danger. By connecting users with support networks and professional services, App-Elles is empowering women to reclaim their safety and seek help when needed.Diata also runs writing and recording workshops to help victims overcome their experiences with violence and has plans to expand her app with the introduction of a discreet wearable that sends out alerts. “I realized from my work on the ground that there were victims of violence who needed help and support systems. This was my inspiration to create App-Elles." Discover more #WeArePlay stories and share your favorites. 
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
20th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Build with Google AI video series, Season 2: more AI patterns | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Joe Fernandez – Google AI Developer Relations

We are off to another exciting year in Artificial Intelligence (AI) and it's time to build more applications with Google AI technology! The Build with Google AI video series is for developers looking to build helpful and practical applications with AI. We focus on useful code projects you can implement and extend in an afternoon to bring the power of artificial intelligence into your workflow or organization. Our first season received over 100,000 views in six weeks! We are glad to see that so many of you liked the series, and we are excited to bring you even more Google AI application projects. Today, we are launching Season 2 of the Build with Google AI series, featuring projects built with Google's Gemini API technology. The launch of Gemini and the Gemini API has brought developers even more advanced AI capabilities, including advanced reasoning, content generation, information synthesis, and image interpretation. Our goal with this season is to help you put those capabilities to work for you and your organizations. AI app patternsThe Build with Google AI series features practical application code projects created for you to use and customize. However, we know that you are the best judge of what you or your organization needs to solve day-to-day problems and get work done. That's why each application we feature in this series is also meant to be used as an AI pattern. You can extend the applications immediately to solve problems and provide value for your business, and these applications show you a general coding pattern for getting value out of AI technology. For this second season of this series, we show how you can leverage Google's Gemini AI model capabilities for applications. Here's what's coming up:
Season 1 upgraded to Gemini API: We've upgraded Season 1 tutorials and code projects to use the Gemini API so you can take advantage of the latest in generative AI technology from Google. Check them out! Learn from the developersJust like last season, we'll go back to the studio to talk with coders who built these projects so they can share what they learned along the way. How do you make the Gemini model review an entire presentation? What's the most effective way to generate code with AI? How do you get a database to answer questions with the Gemini API? Get insights into coding with AI to jump start your own development project. New home for AI developer contentDevelopers interested in Google's AI offerings now have a new home at ai.google.dev. There you'll find a wealth of resources for building with AI from Google, including the Build with Google AI tutorials. Stay tuned for much more content through the rest of the year. We are excited to bring you the second season of Build with Google AI – check out Season 2 right now! Use those video comments to let us know what you think and tell us what you'd like to see in future episodes. Keep learning! Keep building!
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
19th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Tune Gemini Pro in Google AI Studio or with the Gemini API | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Cher Hu, Product Manager and Saravanan Ganesh, Software Engineer for Gemini API

The following post was originally published in October 2023. Today, we've updated the post to share how you can easily tune Gemini models in Google AI Studio or with the Gemini API. Last year, we launched Gemini 1.0 Pro, our mid-sized multimodal model optimized for scaling across a wide range of tasks. And with 1.5 Pro this year, we demonstrated the possibilities of what large language models can do with an experimental 1M context window. Now, to quickly and easily customize the generally available Gemini 1.0 Pro model (text) for your specific needs, we’ve added Gemini Tuning to Google AI Studio and the Gemini API. What is tuning?Developers often require higher quality output for custom use cases than what can be achieved through few-shot prompting. Tuning improves on this technique by further training the base model on many more task-specific examples—so many that they can’t all fit in the prompt. Fine-tuning vs. Parameter Efficient TuningYou may have heard about classic “fine-tuning” of models. This is where a pre-trained model is adapted to a particular task by training it on a smaller set of task-specific labeled data. But with today’s LLMs and their huge number of parameters, fine-tuning is complex: it requires machine learning expertise, lots of data, and lots of compute. Tuning in Google AI Studio uses a technique called Parameter Efficient Tuning (PET) to produce higher-quality customized models with lower latency compared to few-shot prompting and without the additional costs and complexity of traditional fine-tuning. In addition, PET produces high quality models with as little as a few hundred data points, reducing the burden of data collection for the developer. Why tuning?Tuning enables you to customize Gemini models with your own data to perform better for niche tasks while also reducing the context size of prompts and latency of the response. Developers can use tuning for a variety of use cases including but not limited to:
Get started quickly with Google AI Studio1. Create a tuned modelIt’s easy to tune models in Google AI Studio. This removes any need for engineering expertise to build custom models. Start by selecting “New tuned model” in the menu bar on the left.
2. Select data for tuningYou can tune your model from an existing structured prompt or import data from Google Sheets or a CSV file. You can get started with as few as 20 examples and to get the best performance, we recommend providing a dataset of at least 100 examples.
3. View your tuned modelView your tuning progress in your library. Once the model has finished tuning, you can view the details by clicking on your model. Start running your tuned model through a structured or freeform prompt.
4. Run your tuned model anytimeYou can also access your newly tuned model by creating a new structured or freeform prompt and selecting your tuned model from the list of available models.
Tuning with the Gemini APIGoogle AI Studio is the fastest and easiest way to start tuning Gemini models. You can also access the feature via the Gemini API by passing the training data in the API request when creating a tuned model. Learn more about how to get started here. We’re excited about the possibilities that tuning opens up for developers and can’t wait to see what you build with the feature. If you’ve got some ideas or use cases brewing, share them with us on X (formerly known as Twitter) or Linkedin.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
14th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Tune in for Google I/O on May 14 | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations

Google I/O is arriving this year on May 14th and you’re invited to join us online! I/O offers something for everyone, whether you are developing a new application, modernizing an existing one, or transforming it into a business. The Gemini era unlocks new possibilities for developers to build creative and productive AI-enabled applications. I/O is where you’ll hear how you can get from idea to production AI applications faster. We’re excited to share what’s new for mobile, web, and multiplatform development, and how to scale your applications in the cloud. You will be able to dive deeper into topics that interest you with over 100 sessions, workshops, codelabs, and demos. Visit the Google I/O site and register to stay informed about I/O and other related events coming soon. The livestreamed keynotes start May 14 at 10am PT, so mark your calendar. If you haven’t already, go try out our newest Google I/O puzzle and head to @googlefordevs on Instagram if you need a hint.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
13th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| GDE Women’s History Month Feature: Gema Parreño Piqueras, AI/ML GDE | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Justyna Politanska-Pyszko – Program Manager, Google Developer Experts

For Women's History Month, we're shining a spotlight on Gema Parreño Piqueras, an AI/ML Google Developer Expert (GDE) from Madrid, Spain. GDEs are recognized by Google for their outstanding technical expertise and passion for sharing knowledge.
Gema's dedication to the GDE program makes her a true leader within the Google Developers community, and her work in Artificial Intelligence and Machine Learning pushes the boundaries of Google's technological capabilities. Gema is a force to be reckoned with in the world of data science. As a data scientist at Izertis and a GDE, she's not only making significant contributions to the field of AI/ML but also blazing a trail for women in tech. Her unique background in architecture and her passion for problem-solving led her to an impressive career in AI/ML and development of her extraordinary project – helping NASA track asteroids! Learn more about her projects incorporating AI: NASA Project: Deep AsteroidGema's architectural skills proved invaluable when she turned her attention to AI. In 2016, she created the program Deep Asteroid for NASA's International Space Apps Challenge. This innovative program assists scientists in detecting, tracking, and classifying asteroids, potentially protecting our planet from future threats. Journey to AI/MLIntrigued by the potential of AI, Gema embarked on a journey that merged her architectural background with cutting-edge technology. Her experience with 3D modeling translated seamlessly into the world of machine learning, giving her a fresh perspective. Over the past seven years, she's overcome challenges and established herself as a true expert. As a Google Developer Expert, Gema has found a vibrant community that has fueled her growth. She has attended numerous GDE events throughout Europe and had the opportunity to collaborate with Google teams. This experience was instrumental in the development of Deep Asteroid, demonstrating the power of community and access to advanced technology. Gema’s advice for women aspiring to enter the field is simple and powerful: "Don't be afraid to experiment, fail, and learn from those failures. Persistence and a willingness to dive into the unknown are what will set you apart." Gema encourages women to find supportive communities, like the GDE program, where they can network, learn, and grow. You can find Gema on LinkedIn, GitHub and X (formerly known as twitter). The Google Developer Experts (GDE) program is a global network of highly experienced technology experts, influencers, and thought leaders who actively support developers, companies, and tech communities by speaking at events and publishing content.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
12th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Google for Games is coming to GDC 2024 | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Aurash Mahbod – General Manager, Games on Google Play

Google for Games is coming to GDC in San Francisco! Join us on March 19 for the Game Developers Conference (GDC) at the Moscone Center, where game developers from across the world will gather to learn, network, problem-solve, and help shape the future of the industry. From March 18 to March 22, experience our comprehensive suite of multi-platform game development tools and explore the new features from Play Pass at the West Hall, Level 2 Lobby. This year, we’re proud to host eight sessions for developers, designers, business and marketing teams, and everyone else in the gaming community with an interest to grow their game business. Take a look at this year’s sessions below and if you’re interested in learning more about topics from Google Play and Android, check out key product updates from the Google for Games Developer Summit. Scaling your game developmentWe’re hosting three sessions designed to help scale your game development using tools from Firebase, Android, and Google Cloud. Learn more about building high quality games with case studies from industry experts. Beyond "Set and Forget": Advanced Debugging with Firebase CrashlyticsTuesday, March 19, 9:30 am - 10:00 am Speaker: Joe Spiro (Developer Relations Engineer, Google) Crashlytics has added a number of features that make detecting, tracking, and understanding bugs even easier, from high-level to native code. Take your fixes to another level with native stack traces, memory debugging, issue annotation, and the ability to log uncaught exceptions as fatal. Enhancing Game Performance: Vulkan and Android Adaptability TechnologyTuesday, March 19, 10:50 am - 11:50 am Speakers: Dohyun Kim (Developer Relations Engineer, Android Games, Google), Hak Matsuda (Developer Relations Engineer, Android Games, Google), Jungwoo Kim (Principal Engineer, Samsung), Syed Farhan Hassan (Software Engineer, ARM) Learn how to leverage Vulkan graphics API to improve your graphics quality or performance, including performance tuning with dynamic upscaling. Find out how the Android Dynamic Performance Framework (ADPF) can enhance game performance and power in Unity and native C++, with easy integration through the Unreal Engine plugin. We're also sharing how NCSoft Lineage W improved thermal status and performance using ADPF. Creating a global-scale game with Google CloudTuesday, March 19, 4:40 pm - 5:10 pm Speaker: Mark Mandel (Developer Advocate, Google) This session will cover the best of Google Cloud's open source projects (Agones, Open Match, and more) and products (GKE, Spanner, Anthos Service Mesh, Cloud Build, Cloud Deploy, and more) to teach you how to build, deploy, and scale world-scale multiplayer games with Google Cloud. Increasing user engagementWe’re hosting two sessions designed to help you increase engagement by creating dynamic gameplay experiences using generative AI and expanding opportunities on Google Play to grow your community of players with exclusive rewards. Reimagine the Future of Gaming with Google AITuesday, March 19, 10:50 am - 11:50 am Speakers: Gus Martins (Developer Advocate, Google), Dan Zaratsian (AI/ML Solutions Architect, Google), Lei Zhang (Director, Play Partnerships, Global GenAI & Greater China Play Partnerships, Google), Jack Buser (Director, Game Industry Solutions), Simon Tokumine (Director of Product Management, Google AI), Giovane Moura Jr. (App Modernization Specialist, Google), Moonlit Beshinov (Head of Google for Games Partnerships and Industry Strategy, Google) In our keynote session, senior executives from Google Cloud, Google Play, and Labs will share their unique perspectives on generative AI in the gaming landscape. Learn more about cutting-edge AI solutions from Google Cloud, Android, Google Play, and Labs designed to simplify game development, publishing, and business operations, plus actionable strategies to leverage AI for faster development, better player experiences, and sustainable growth. Grow your community of loyal gamers with Google PlayTuesday, March 19, 1:20 pm - 1:50 pm Speaker: Tom Grinsted (Group Product Manager, Google Play Games, Google) In this session, we’ll cover new features and insights from Google Play to create rewarding experiences for gamers using Play Pass, Play Points, and Play Games Services. Get a behind-the-scenes look at how Google Play rewards a growing community of passionate gamers, and how to use this to super-charge your business. Maximizing reach across screensThese sessions, from Google Play, Android, and Flutter, introduce ways to expand your mobile games to PC. Learn about the latest tools that will help you accelerate growth across large screens. Bringing more users to your Google Play Games on PC gameTuesday, March 19, 2:10 pm - 2:40 pm Speakers: Aly Hung (Developer Relations Engineer, Android and Google Play, Google), Dara Monasch (Product Manager, Google), Justin Gardner (Partner Program Manager, App Attribution, Google) Join us for an overview of Google Play Games on PC, how it has grown in the past year, and a walkthrough of how to optimize and attribute your PC advertisements for your Google Play Games on PC titles. Learn how to use Google Play Games to increase your reach and acquisition of PC users for your mobile game, as well as how to effectively use the Google Play Install Referrer API to attribute and optimize your ads across mobile and PC. Android input on desktop: How to delight your usersTuesday, March 19, 3:00 pm - 3:30 pm Speakers: Shenshen Cui (Staff Developer Relations Engineer, Google), Patrick Martin (Developer Relations Engineer, Google) Give your players a first-class gaming experience with our best practices for handling input between mobile and PC games, including technical details on how to implement these best practices across mobile, tablets, Chromebooks and Windows PCs1. Learn how Android handles keyboard, mouse, and controller input across different form factors, with case studies for designing for both touch and hardware input. Building Multiplatform Games with FlutterTuesday, March 19, 3:50 pm - 4:20 pm Speakers: Zoey Fan (Senior Product Manager, Flutter, Google), Brett Morgan (Developer Relations Engineer, Google) Learn why game developers are choosing Flutter to build casual games on mobile, desktop, and web browsers. We’ll cover the free, open-source tools and resources available through the Casual Games Toolkit, a collection of free and open-source tools, templates, and resources to make game dev more productive with Flutter. Learn more about all of our sessions coming to you on March, 19, at GDC in San Francisco. ________________ 1Windows is a trademark of the Microsoft group of companies.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
7th March 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Large Language Models On-Device with MediaPipe and TensorFlow Lite | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Mark Sherwood – Senior Product Manager and Juhyun Lee – Staff Software Engineer

TensorFlow Lite has been a powerful tool for on-device machine learning since its release in 2017, and MediaPipe further extended that power in 2019 by supporting complete ML pipelines. While these tools initially focused on smaller on-device models, today marks a dramatic shift with the experimental MediaPipe LLM Inference API. This new release enables Large Language Models (LLMs) to run fully on-device across platforms. This new capability is particularly transformative considering the memory and compute demands of LLMs, which are over a hundred times larger than traditional on-device models. Optimizations across the on-device stack make this possible, including new ops, quantization, caching, and weight sharing. The experimental cross-platform MediaPipe LLM Inference API, designed to streamline on-device LLM integration for web developers, supports Web, Android, and iOS with initial support for four openly available LLMs: Gemma, Phi 2, Falcon, and Stable LM. It gives researchers and developers the flexibility to prototype and test popular openly available LLM models on-device. On Android, the MediaPipe LLM Inference API is intended for experimental and research use only. Production applications with LLMs can use the Gemini API or Gemini Nano on-device through Android AICore. AICore is the new system-level capability introduced in Android 14 to provide Gemini-powered solutions for high-end devices, including integrations with the latest ML accelerators, use-case optimized LoRA adapters, and safety filters. To start using Gemini Nano on-device with your app, apply to the Early Access Preview. LLM Inference APIStarting today, you can test out the MediaPipe LLM Inference API via our web demo or by building our sample demo apps. You can experiment and integrate it into your projects via our Web, Android, or iOS SDKs. Using the LLM Inference API allows you to bring LLMs on-device in just a few steps. These steps apply across web, iOS, and Android, though the SDK and native API will be platform specific. The following code samples show the web SDK.
Please see our documentation and code examples for a detailed walk through of each of these steps. Here are real time gifs of Gemma 2B running via the MediaPipe LLM Inference API.
ModelsOur initial release supports the following four model architectures. Any model weights compatible with these architectures will work with the LLM Inference API. Use the base model weights, use a community fine-tuned version of the weights, or fine tune weights using your own data.
Model PerformanceThrough significant optimizations, some of which are detailed below, the MediaPipe LLM Inference API is able to deliver state-of-the-art latency on-device, focusing on CPU and GPU to support multiple platforms. For sustained performance in a production setting on select premium phones, Android AICore can take advantage of hardware-specific neural accelerators. When measuring latency for an LLM, there are a few terms and measurements to consider. Time to First Token and Decode Speed will be the two most meaningful as these measure how quickly you get the start of your response and how quickly the response generates once it starts.
The Prefill Speed and Decode Speed are dependent on model, hardware, and max tokens. They can also change depending on the current load of the device. The following speeds were taken on high end devices using a max tokens of 1280 tokens, an input prompt of 1024 tokens, and int8 weight quantization. The exception being Gemma 2B (int4), found here on Kaggle, which uses a mixed 4/8-bit weight quantization. Benchmarks
Performance OptimizationsTo achieve the performance numbers above, countless optimizations were made across MediaPipe, TensorFlow Lite, XNNPack (our CPU neural network operator library), and our GPU-accelerated runtime. The following are a select few that resulted in meaningful performance improvements. Weights Sharing: The LLM inference process comprises 2 phases: a prefill phase and a decode phase. Traditionally, this setup would require 2 separate inference contexts, each independently managing resources for its corresponding ML model. Given the memory demands of LLMs, we've added a feature that allows sharing the weights and the KV cache across inference contexts. Although sharing weights might seem straightforward, it has significant performance implications when sharing between compute-bound and memory-bound operations. In typical ML inference scenarios, where weights are not shared with other operators, they are meticulously configured for each fully connected operator separately to ensure optimal performance. Sharing weights with another operator implies a loss of per-operator optimization and this mandates the authoring of new kernel implementations that can run efficiently even on sub-optimal weights. Optimized Fully Connected Ops: XNNPack’s FULLY_CONNECTED operation has undergone two significant optimizations for LLM inference. First, dynamic range quantization seamlessly merges the computational and memory benefits of full integer quantization with the precision advantages of floating-point inference. The utilization of int8/int4 weights not only enhances memory throughput but also achieves remarkable performance, especially with the efficient, in-register decoding of 4-bit weights requiring only one additional instruction. Second, we actively leverage the I8MM instructions in ARM v9 CPUs which enable the multiplication of a 2x8 int8 matrix by an 8x2 int8 matrix in a single instruction, resulting in twice the speed of the NEON dot product-based implementation. Balancing Compute and Memory: Upon profiling the LLM inference, we identified distinct limitations for both phases: the prefill phase faces restrictions imposed by the compute capacity, while the decode phase is constrained by memory bandwidth. Consequently, each phase employs different strategies for dequantization of the shared int8/int4 weights. In the prefill phase, each convolution operator first dequantizes the weights into floating-point values before the primary computation, ensuring optimal performance for computationally intensive convolutions. Conversely, the decode phase minimizes memory bandwidth by adding the dequantization computation to the main mathematical convolution operations.
Custom Operators: For GPU-accelerated LLM inference on-device, we rely extensively on custom operations to mitigate the inefficiency caused by numerous small shaders. These custom ops allow for special operator fusions and various LLM parameters such as token ID, sequence patch size, sampling parameters, to be packed into a specialized custom tensor used mostly within these specialized operations. Pseudo-Dynamism: In the attention block, we encounter dynamic operations that increase over time as the context grows. Since our GPU runtime lacks support for dynamic ops/tensors, we opt for fixed operations with a predefined maximum cache size. To reduce the computational complexity, we introduce a parameter enabling the skipping of certain value calculations or the processing of reduced data. Optimized KV Cache Layout: Since the entries in the KV cache ultimately serve as weights for convolutions, employed in lieu of matrix multiplications, we store these in a specialized layout tailored for convolution weights. This strategic adjustment eliminates the necessity for extra conversions or reliance on unoptimized layouts, and therefore contributes to a more efficient and streamlined process. What’s NextWe are thrilled with the optimizations and the performance in today’s experimental release of the MediaPipe LLM Inference API. This is just the start. Over 2024, we will expand to more platforms and models, offer broader conversion tools, complimentary on-device components, high level tasks, and more. You can check out the official sample on GitHub demonstrating everything you’ve just learned about and read through our official documentation for even more details. Keep an eye on the Google for Developers YouTube channel for updates and tutorials. AcknowledgementsWe’d like to thank all team members who contributed to this work: T.J. Alumbaugh, Alek Andreev, Frank Ban, Jeanine Banks, Frank Barchard, Pulkit Bhuwalka, Buck Bourdon, Maxime Brénon, Chuo-Ling Chang, Lin Chen, Linkun Chen, Yu-hui Chen, Nikolai Chinaev, Clark Duvall, Rosário Fernandes, Mig Gerard, Matthias Grundmann, Ayush Gupta, Mohammadreza Heydary, Ekaterina Ignasheva, Ram Iyengar, Grant Jensen, Alex Kanaukou, Prianka Liz Kariat, Alan Kelly, Kathleen Kenealy, Ho Ko, Sachin Kotwani, Andrei Kulik, Yi-Chun Kuo, Khanh LeViet, Yang Lu, Lalit Singh Manral, Tyler Mullen, Karthik Raveendran, Raman Sarokin, Sebastian Schmidt, Kris Tonthat, Lu Wang, Zoe Wang, Tris Warkentin, Geng Yan, Tenghui Zhu, and the Gemma team.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
26th February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Google Cloud Next '24 session library is now available | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Max Saltonstall – Developer Relations Engineer

Google Cloud Next 2024 is coming soon, and our session library is live! Next ‘24 covers a ton of ground, so choose your adventure. There's something on the menu for everyone, not just AI. Developer-focusedDevelopers, this is your time. We have got a huge collection of edutainment for you in store for Next, including:
This year we have more than double the number of advanced technical sessions, and recommendations for startups, small and medium businesses, and sustainability for all. Data scientists and data engineers can shard themselves out into 60+ big data sessions, including going to the cutting edge with BigQuery multi-modal data. Artificial intelligenceIf you want to build your own AI model, LLM or chatbot we've got sessions for that, covering ways to use Vertex AI to spin up your own large-language models on cloud, to search your multimedia library and to maintain equity in your data used for training. Diversity, equity, and inclusionEquity and inclusion go way past AI, and we’re really excited to have talks this year addressing allyship for your Muslim colleagues, growing inclusion in your org, and dialogues for change.
Security and data privacyDon't forget security (really, who does?). Whether you are tackling security at the infrastructure, platform, machine or workload level, we've got sessions for you. Even if you're on multiple clouds, with multiple teams, you still need to get insight into the security and compliance of it all. Speaking of all these fun chips, what about the salsa? We've got supply chain security with talks on SLSA and GUAC, plus numerous options for serverless workload security and ML data privacy. Come join usSo, still on the fence? Come for the magnificent shows in Vegas. Come for the chance to sit down with expert developers and engineers. Come for the amazing technical talks and tutorials. Or just come for the spectacle. We've got it all at Google Cloud Next ‘24. Check out sessions and secure your spot for three days of learning, community-building, and cloud tech with experts and peers at Mandalay Bay Convention Center in Las Vegas, April 9–11.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
21st February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Introducing Gemma models in Keras | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Martin Görner – Product Manager, Keras

The Keras team is happy to announce that Gemma, a family of lightweight, state-of-the art open models built from the same research and technology that we used to create the Gemini models, is now available in the KerasNLP collection. Thanks to Keras 3, Gemma runs on JAX, PyTorch and TensorFlow. With this release, Keras is also introducing several new features specifically designed for large language models: a new LoRA API (Low Rank Adaptation) and large scale model-parallel training capabilities. If you want to dive directly into code samples, head here:
Get startedGemma models come in portable 2B and 7B parameter sizes, and deliver significant advances against similar open models, and even some larger ones. For example:
Gemma models are offered with a familiar KerasNLP API and a super-readable Keras implementation. You can instantiate the model with a single line of code: gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
And run it directly on a text prompt – yes, tokenization is built-in, although you can easily split it out if needed - read the Keras NLP guide to see how. gemma_lm.generate("Keras is a", max_length=32)
> "Keras is a popular deep learning framework for neural networks..."
Try it out here: Get started with Gemma models Fine-tuning Gemma Models with LoRAThanks to Keras 3, you can choose the backend on which you run the model. Here is how to switch: os.environ["KERAS_BACKEND"] = "jax" # Or "tensorflow" or "torch".
import keras # import keras after having selected the backend
Keras 3 comes with several new features specifically for large language models. Chief among them is a new LoRA API (Low Rank Adaptation) for parameter-efficient fine-tuning. Here is how to activate it: gemma_lm.backbone.enable_lora(rank=4)
# Note: rank=4 replaces the weights matrix of relevant layers with the
# product AxB of two matrices of rank 4, which reduces the number of
# trainable parameters.
This single line drops the number of trainable parameters from 2.5 billion to 1.3 million! Try it out here: Fine-tune Gemma models with LoRA. Fine-tuning Gemma models on multiple GPU/TPUsKeras 3 also supports large-scale model training and Gemma is the perfect model to try it out. The new Keras distribution API offers data-parallel and model-parallel distributed training options. The new API is meant to be multi-backend but for the time being, it is implemented for the JAX backend only, because of its proven scalability (Gemma models were trained with JAX). To fine-tune the larger Gemma 7B, a distributed setup is useful, for example a TPUv3 with 8 TPU cores that you can get for free on Kaggle, or an 8-GPU machine from Google Cloud. Here is how to configure the model for distributed training, using model parallelism: device_mesh = keras.distribution.DeviceMesh(
(1, 8), # Mesh topology
["batch", "model"], # named mesh axes
devices=keras.distribution.list_devices() # actual accelerators
)
# Model config
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = (None, "model")
layout_map["decoder_block.*attention.*(query|key|value).*kernel"] = (
None, "model", None)
layout_map["decoder_block.*attention_output.*kernel"] = (
None, None, "model")
layout_map["decoder_block.*ffw_gating.*kernel"] = ("model", None)
layout_map["decoder_block.*ffw_linear.*kernel"] = (None, "model")
# Set the model config and load the model
model_parallel = keras.distribution.ModelParallel(
device_mesh, layout_map, batch_dim_name="batch")
keras.distribution.set_distribution(model_parallel)
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_7b_en")
# Ready: you can now train with model.fit() or generate text with generate()
What this code snippet does is set up the 8 accelerators into a 1 x 8 matrix where the two dimensions are called “batch” and “model”. Model weights are sharded on the “model” dimension, here split between the 8 accelerators, while data batches are not partitioned since the “batch” dimension is 1. Try it out here: Fine-tune Gemma models on multiple GPUs/TPUs. What’s NextWe will soon be publishing a guide showing you how to correctly partition a Transformer model and write the 6 lines of partitioning setup above. It is not very long but it would not fit in this post. You will have noticed that layer partitionings are defined through regexes on layer names. You can check layer names with this code snippet. We ran this to construct the LayoutMap above. # This is for the first Transformer block only,
# but they all have the same structure
tlayer = gemma_lm.backbone.get_layer('decoder_block_0')
for variable in tlayer.weights:
print(f'{variable.path:<58} {str(variable.shape):<16}')
Full GSPMD model parallelism works here with just a few partitioning hints because Keras passes these settings to the powerful XLA compiler which figures out all the other details of the distributed computation. We hope you will enjoy playing with Gemma models. Here is also an instruction-tuning tutorial that you might find useful. And by the way, if you want to share your fine-tuned weights with the community, the Kaggle Model Hub now supports user-tuned weights uploads. Head to the model page for Gemma models on Kaggle and see what others have already created!
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
16th February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Build with Gemini models in Project IDX | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Ali Satter – AI Lead, Roman Nurik – Design Lead, Kaushik Sathupadi and Jamal Carvalho – AI Engineers

A few weeks ago, we announced a series of product updates to Project IDX to help streamline and simplify full-stack, multiplatform software development. This week, we’re excited to share how Project IDX uses Gemini models to provide you with AI features to further speed up and refine your end-to-end developer workflow. Project IDX launched with support for AI-powered code completion, an assistive chatbot, and contextual code actions like "add comments" and “explain this code” to help you write high-quality code faster. Since launch, and thanks to your feedback, we’ve been working hard to add new AI functionality to help boost your productivity even more. Work faster with inline AI assistanceYou can now get inline AI assistance inside any file by pressing Cmd/Ctrl + I. Simply describe the changes you want to make to your code and IDX inline AI assistance will provide real-time error correction, code suggestions, and auto-completion in your code. We integrated these AI enhancements directly into Project IDX’s centralized workspace to equip you with the necessary tools and resources for full-stack app development where and when you need them. From setting up your workspace to testing your app, IDX AI assistance helps accelerate and improve your workflow, ensuring that your end-to-end development experience is faster, easier, and higher quality. For example, let’s say you want to add an authenticated API endpoint to your server. You can tell IDX AI to write the code necessary to enable secure task management using Firebase Authentication and Cloud Firestore. Given an input prompt, IDX AI assistance can write the code to construct the route, determine which APIs to use to verify the token, and save the data to the database. Instead of writing boilerplate code, you can focus on higher-level design and problem solving.
Then, let's say you want to clean up your code a bit to improve its quality, readability, and maintainability. IDX AI assistance can help you quickly and easily refactor your code, so you can get right into optimizing your work without the hassle of manual refactoring.
And, as you wrap up your project, IDX AI can help you test and debug your code to make sure your application is running smoothly before deployment. Tell IDX AI assistance to write you a unit test for a function to ensure it’s working properly, saving you time and effort as you inspect the quality of your app.
Easily add AI features with the Gemini API templateWe’re also simplifying the process of building with the Gemini API with Project IDX’s new Gemini API template. The Gemini API template uses the Gemini Pro model to embed AI-powered features into your applications without additional configuration on your end, so you can get started working with the Gemini API quickly and easily. There's even an option to use the Gemini API via the popular LangChain framework to simplify the process of building LLM-powered apps. The Gemini API template is multimodal, meaning it can provide context-aware prompt output for a myriad of input modalities including images, text and, of course, code. This can help you add features like conversational interfaces, summarization of user reviews, translation, and automatic image caption creation. To demonstrate its functionality, we pre-configured the Gemini API template with ‘Baking with the Gemini API’, a recipe builder application that, using the Gemini model’s multimodal capabilities, can reverse-engineer possible recipes for baked goods from just a picture.
But this recipe builder is just one example of the Gemini API template in action – with support for different input modalities and context-aware output generation, you can use IDX’s Gemini API template to create a myriad of innovative and impactful applications that deliver AI-enhanced experiences to your users. Stay tuned for more AI updatesThese updates are a continuation of our efforts to leverage Google’s AI innovations for Project IDX, so make sure to keep an eye out for more announcements to come, including the expansion of AI in IDX to more than 150 countries/regions in the coming weeks. Thank you for your continued support and engagement – please keep the feedback coming by filing bugs and feature requests. For walkthroughs and more information on all the features mentioned above, check out our documentation. If you haven’t already, visit our website to sign up to try Project IDX and join us on our journey. Also, be sure to check out our new Project IDX Blog for the latest product announcements and updates from the team. We can’t wait to see what you create with Project IDX!
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
15th February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Gemini 1.5: Our next-generation model, now available for Private Preview in Google AI Studio | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Jaclyn Konzelmann and Wiktor Gworek – Google Labs

Last week, we released Gemini 1.0 Ultra in Gemini Advanced. You can try it out now by signing up for a Gemini Advanced subscription. The 1.0 Ultra model, accessible via the Gemini API, has seen a lot of interest and continues to roll out to select developers and partners in Google AI Studio. Today, we’re also excited to introduce our next-generation Gemini 1.5 model, which uses a new Mixture-of-Experts (MoE) approach to improve efficiency. It routes your request to a group of smaller "expert” neural networks so responses are faster and higher quality. Developers can sign up for our Private Preview of Gemini 1.5 Pro, our mid-sized multimodal model optimized for scaling across a wide-range of tasks. The model features a new, experimental 1 million token context window, and will be available to try out in Google AI Studio. Google AI Studio is the fastest way to build with Gemini models and enables developers to easily integrate the Gemini API in their applications. It’s available in 38 languages across 180+ countries and territories. 1,000,000 tokens: Unlocking new use cases for developersBefore today, the largest context window in the world for a publicly available large language model was 200,000 tokens. We’ve been able to significantly increase this — running up to 1 million tokens consistently, achieving the longest context window of any large-scale foundation model. Gemini 1.5 Pro will come with a 128,000 token context window by default, but today’s Private Preview will have access to the experimental 1 million token context window. We’re excited about the new possibilities that larger context windows enable. You can directly upload large PDFs, code repositories, or even lengthy videos as prompts in Google AI Studio. Gemini 1.5 Pro will then reason across modalities and output text.
More ways for developers to build with Gemini modelsIn addition to bringing you the latest model innovations, we’re also making it easier for you to build with Gemini:
Since December, developers of all sizes have been building with Gemini models, and we’re excited to turn cutting edge research into early developer products in Google AI Studio. Expect some latency in this preview version due to the experimental nature of the large context window feature, but we’re excited to start a phased rollout as we continue to fine-tune the model and get your feedback. We hope you enjoy experimenting with it early on, like we have.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
12th April 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Google Pay - Enabling liability shift for eligible Visa device token transactions globally | ||||||||||||||||||||||||||||||||||||||||||||||||
|
Posted by Dominik Mengelt– Developer Relations Engineer, Payments and Florin Modrea - Product Solutions Engineer, Google Pay
We are excited to announce the general availability [1] of liability shift for Visa device tokens for Google Pay. For Mastercard device tokens the liability already lies with the issuing bank, whereas, for Visa, only eligible device tokens with issuing banks in the European region benefit from liability shift. What is liability shift?If liability shift is granted for a transaction, the responsibility of covering the losses from fraudulent transactions is moving from the merchant to the issuing bank. With this change, qualifying Google Pay Visa transactions done with a device token will benefit from this liability shift. How to know if the liability was shifted to the issuing bank for my transaction?Eligible Visa transactions will carry an eciIndicator value of 05. PSPs can access the eciIndicator value after decrypting the payment method token. Merchants can check with their PSPs to get a report on liability shift eligible transactions. {
"gatewayMerchantId": "some-merchant-id",
"messageExpiration": "1561533871082",
"messageId": "AH2Ejtc8qBlP_MCAV0jJG7Er",
"paymentMethod": "CARD",
"paymentMethodDetails": {
"expirationYear": 2028,
"expirationMonth": 12,
"pan": "4895370012003478",
"authMethod": "CRYPTOGRAM_3DS",
"eciIndicator": "05",
"cryptogram": "AgAAAAAABk4DWZ4C28yUQAAAAAA="
}
}
Check out the following table for a full list of eciIndicator values we return for our Visa and Mastercard device token transactions:
Any other eciIndicator values for VISA and Mastercard that aren't present in this table won't be returned. How to enrollMerchants may opt-in from within the Google Pay & Wallet console starting this month. Merchants in Europe (already benefiting from liability shift) do not need to take any actions as they will be auto enrolled. In order for your Google Pay transaction to qualify for enabling liability shift, the following API parameters are required:
Not all transactions get liability shiftIneligible merchantsIn the US, the following MCC codes are excluded from getting liability shift:
Ineligible transactionsIn order for your Google Pay transactions to qualify for liability shift, make sure to include the above mentioned parameters totalPrice and totalPriceStatus. Transactions with totalPrice=0 or a hard coded totalPrice (always the same amount but the users get charged a different amount) will not qualify for liability shift. Additionally, the currency used when initializing Google Pay must match the currency during the authorization. Non matching currencies could lead to declined transactions. Processing transactionsGoogle Pay API transactions with Visa device tokens are qualified for liability shift at facilitation time if all the conditions are met, but a transaction qualified for liability shift can be downgraded by network during transaction authorization processing. Getting started with Google PayNot yet using Google Pay? Refer to the documentation to start integrating Google Pay today. Learn more about the integration by taking a look at our sample application for Android on GitHub or use one of our button components for your web integration. When you are ready, head over to the Google Pay & Wallet console and submit your integration for production access. Follow @GooglePayDevs on X (formerly Twitter) for future updates. If you have questions, tag @GooglePayDevs and include #AskGooglePayDevs in your tweets. [1] For merchants and PSPs using dynamic price updates or other callback mechanisms the Visa device token liability shift changes will be rolled out later this year.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
14th February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| #WeArePlay | How two sea turtle enthusiasts are revolutionizing marine conservation | ||||||||||||||||||||||||||||||||||||||||||||||||
|
Posted by Leticia Lago – Developer Marketing
When environmental science student Caitlin returned home from a trip monitoring sea turtles in Western Australia, she was inspired to create a conservation tool that could improve tracking of the species. She connected with a French developer and fellow marine life enthusiast Nicolas to design their app We Spot Turtles!, allowing anyone to support tracking efforts by uploading pictures of them spotted in the wild. Caitlin and Nicolas shared their journey in our latest film for #WeArePlay, which showcases the amazing stories behind apps and games on Google Play. We caught up with the pair to find out more about their passion and how they are making strides towards advancing sea turtle conservation. Tell us about how you both got interested in sea turtle conservation?Caitlin: A few years ago, I did a sea turtle monitoring program for the Department of Biodiversity, Conservation and Attractions in Western Australia. It was probably one of the most magical experiences of my life. After that, I decided I only really wanted to work with sea turtles. Nicolas: In 2010, in French Polynesia, I volunteered with a sea turtle protection project. I was moved by the experience, and when I came back to France, I knew I wanted to use my tech background to create something inspired by the trip. How did these experiences lead you to create We Spot Turtles!?Caitlin: There are seven species of sea turtle, and all are critically endangered. Or rather there’s not enough data on them to inform an accurate endangerment status. This means the needs of the species are going unmet and sea turtles are silently going extinct. Our inspiration is essentially to better track sea turtles so that conservation can be improved. Nicolas: When I returned to France after monitoring sea turtles, I knew I wanted to make an app inspired by my experience. However, I had put the project on hold for a while. Then, when a friend sent me Caitlin’s social media post looking for a developer for a sea turtle conservation app, it re-ignited my inspiration, and we teamed up to make it together.
What does We Spot Turtles! do?Caitlin: Essentially, members of the public upload images of sea turtles they spot – and even get to name them. Then, the app automatically geolocates, giving us a date and timestamp of when and where the sea turtle was located. This allows us to track turtles and improve our conservation efforts. How do you use artificial intelligence in the app?Caitlin: The advancements in AI in recent years have given us the opportunity to make a bigger impact than we would have been able to otherwise. The machine learning model that Nicolas created uses the facial scale and pigmentations of the turtles to not only identify its species, but also to give that sea turtle a unique code for tracking purposes. Then, if it is photographed by someone else in the future, we can see on the app where it's been spotted before. How has Google Play supported your journey?Caitlin: Launching our app on Google Play has allowed us to reach a global audience. We now have communities in Exmouth in Western Australia, Manly Beach in Sydney, and have 6 countries in total using our app already. Without Google Play, we wouldn't have the ability to connect on such a global scale. Nicolas: I’m a mobile application developer and I use Google’s Flutter framework. I knew Google Play was a good place to release our title as it easily allows us to work on the platform. As a result, we’ve been able to make the app great.
What do you hope to achieve with We Spot Turtles!?Caitlin: We Spot Turtles! puts data collection in the hands of the people. It’s giving everyone the opportunity to make an impact in sea turtle conservation. Because of this, we believe that we can massively alter and redefine conservation efforts and enhance people’s engagement with the natural world. What are your plans for the future?Caitlin: Nicolas and I have some big plans. We want to branch out into other species. We'd love to do whale sharks, birds, and red pandas. Ultimately, we want to achieve our goal of improving the conservation of various species and animals around the world. Discover other inspiring app and game founders featured in #WeArePlay.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
13th February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Calling all students: Learn how to become a Google Developer Student Club Lead | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Rachel Francois, Global Program Manager, Google Developer Student Clubs

Does the idea of leading a student community at your university appeal to you? Are you enthusiastic about Google technologies or interested in learning more about them? Do you love planning tech-related events and new ways for your campus community to build skills? If so, consider leading a Google Developer Student Club! What are Google Developer Student Clubs?Google Developer Student Clubs (GDSC) are community groups for university students interested in learning and building with Google technologies. There are over 2000 GDSC chapters, represented in over 100 countries around the world where undergraduate and graduate students explore Artificial Intelligence, Machine Learning, Google Cloud, Android development, Flutter, and other innovative technologies together. GDSC chapters host in-person, project-based events, such as hackathons and Solution Challenge with guest speakers and technical experts provided by Google. Apply to Lead a Google Developer Student ClubYou can learn more about the 2024-2025 GDSC Lead application process here. Leading a GDSC is a great opportunity to learn new programming skills, dive deep into Google technologies and create local impact, while also building your network. Google Developer Student Club Leads hone their technical and leadership skills as they manage a campus-based community for peers. GDSC Leads:
Meet Drashtant Chudasama, Lakehead University Google Developer Student Club lead. Drashtant hosted a 2-day DevFest On Campus event in Canada to help foster technology in his local area. The city's first DevFest included a handful of guest speakers and a hackathon. These are the types of things you will have the opportunity to do as a GDSC Lead. If this sounds like your skill set or you’d like to explore a new leadership opportunity in technology, we encourage you to apply to become a GDSC Lead. You can check for application deadlines in your region here. Google Developer Student Clubs Around the World
After a year’s hiatus, GDSC HITS lead, Amitasha Verma and her team defied the odds to bring an interactive event to life. More than 80+ students came together for a 3-hour "Unlocking the Power of Blockchain" event in India. This event demonstrated the unwavering spirit of students eager to explore the world of blockchain.
GDSC Fast National University in Islamabad collaborated with 15 other GDSC chapters to host the exciting "Techbuzz" competition, bringing together a diverse group of tech enthusiasts to showcase their skills through a variety of engaging activities. The event featured intense rapid-fire tech sessions that tested the participants' knowledge and quick thinking, while bringing a game-based learning platform to add an element of fun and excitement. How to become a GDSC LeadLearn more about the GDSC Lead role and criteria here. To get started click here. Note: Google Developer Student Clubs are student-led independent organizations, and their presence does not indicate a relationship between Google and the students' universities.
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
21st February 2024 | |
||||||||||||||||||||||||||||||||||||||||||||||||
| Federated Credential Management (FedCM) Migration for Google Identity Services | ||||||||||||||||||||||||||||||||||||||||||||||||
Posted by Gina Biernacki, Product Manager

Chrome is phasing out support for third-party cookies this year, subject to addressing any remaining concerns of the CMA. A relatively new web API, Federated Credential Management (FedCM), will enable sign-in for the Google Identity Services (GIS) library after the phase out of third-party cookies. Starting in April, GIS developers will be automatically migrated to the FedCM API. For most developers, this migration will occur seamlessly through backwards-compatible updates to the GIS library. However, some websites with custom integrations may require minor changes. We encourage all developers to experiment with FedCM, as previously announced through the beta program, to ensure flows will not be interrupted. Developers have the ability to temporarily exempt traffic from using FedCM until Chrome enforces the restriction of third-party cookies. AudienceThis update is for all GIS web developers who rely on the Chrome browser and use:
ContextAs part of the Privacy Sandbox initiative to keep people’s activity private and support free experiences for everyone, Chrome is phasing out support for third-party cookies, subject to addressing any remaining concerns of the CMA. Scaled testing began at 1% in January and will continue throughout the year. GIS currently uses third-party cookies to allow users to sign up and sign in to websites easily and securely by reducing reliance on passwords. The FedCM API is a new privacy-preserving alternative to third-party cookies for federated identity providers. It allows Google to continue providing a secure, streamlined experience for signing up and signing in to websites. Last August, the Google Identity team announced a beta program for developers to test the Chrome browser’s new FedCM API supporting GIS. What to Expect in the MigrationPartners who offer GIS’s One Tap and Automatic Sign-In features will automatically be migrated to FedCM in April. For most developers, this migration will occur seamlessly through backwards-compatible updates to the GIS JavaScript library; the GIS library will call the FedCM APIs behind the scenes, without requiring any developer changes. The new FedCM APIs have minimal impact to existing user flows. Some Developers May be Required to Make ChangesSome websites with custom integrations may require minor changes, such as updates to custom layouts or positioning of sign-in prompts. Websites using embedded iframes for sign-in or a non-compliant Content Security Policy may need to be updated. To learn if your website will require changes, please review the migration guide. We encourage you to enable and experiment with FedCM, as previously announced through the beta program, to ensure flows will not be interrupted. Migration TimelineIf you are using GIS One Tap or Automatic Sign-in on your website, please be aware of the following timelines:
Once the Chrome browser restricts third-party cookies by default for all Chrome clients, the use of FedCM will be required for partners who use GIS One Tap and Automatic Sign-In features. Checklist for Developers to Prepare
To get started and learn more about FedCM, visit our developer site and check out the google-signin tag on Stack Overflow for technical assistance. We invite developers to share their feedback with us at gis-fedcm-feedback@google.com.
|
 Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks
Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks


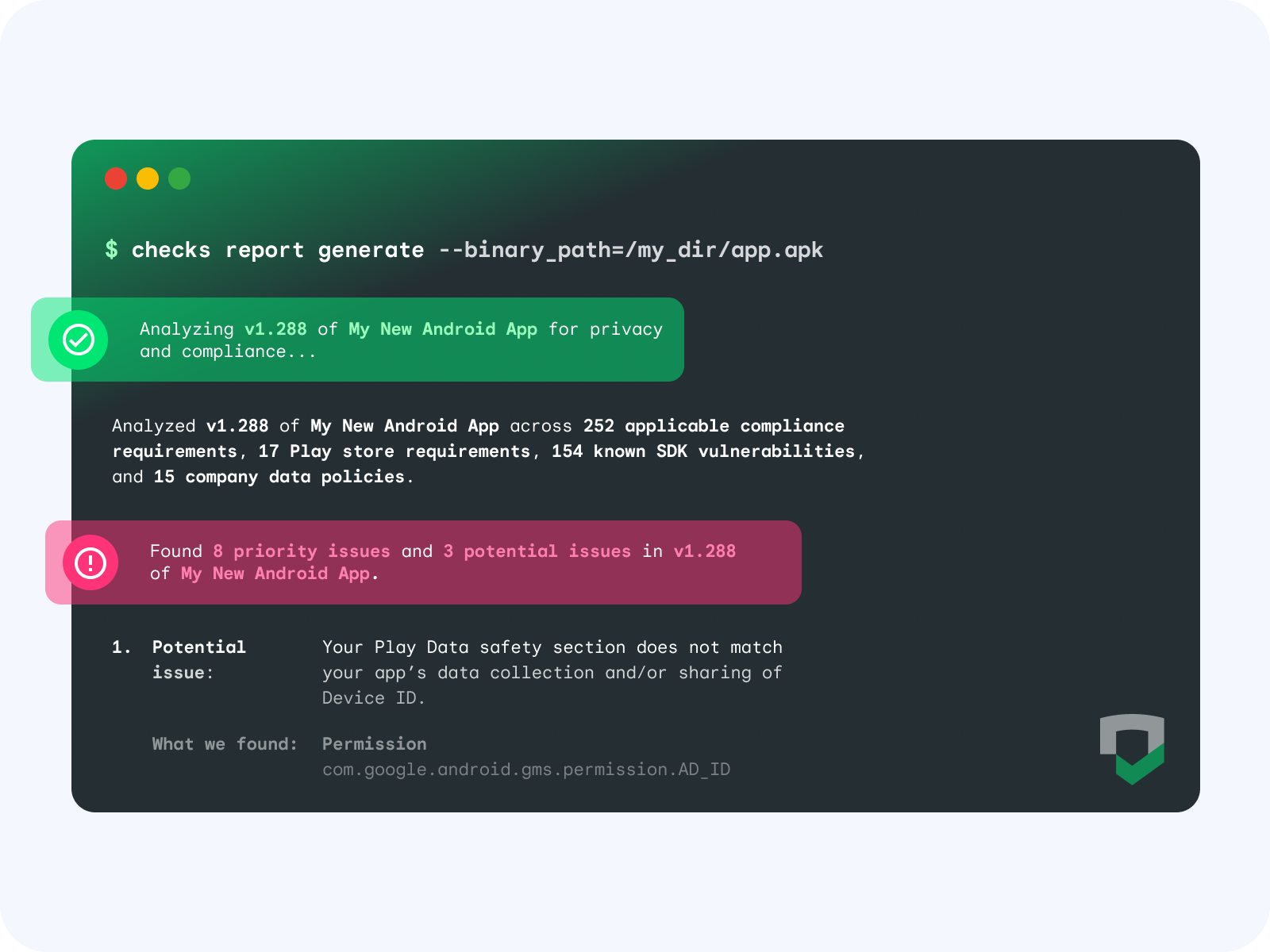




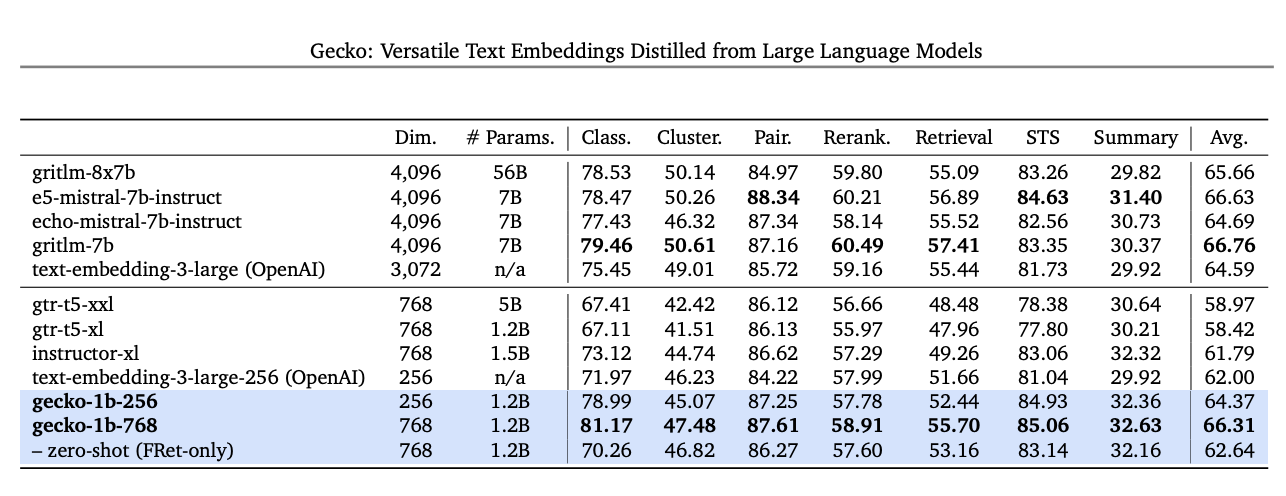
 Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA
Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA
 Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager
Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager


 Posted by Bitnoori Keum – DevRel Community Manager
Posted by Bitnoori Keum – DevRel Community Manager
 Posted by Leticia Lago – Developer Marketing
Posted by Leticia Lago – Developer Marketing
 Posted by Joe Fernandez – Google AI Developer Relations
Posted by Joe Fernandez – Google AI Developer Relations
 Posted by Cher Hu, Product Manager and Saravanan Ganesh, Software Engineer for Gemini API
Posted by Cher Hu, Product Manager and Saravanan Ganesh, Software Engineer for Gemini API


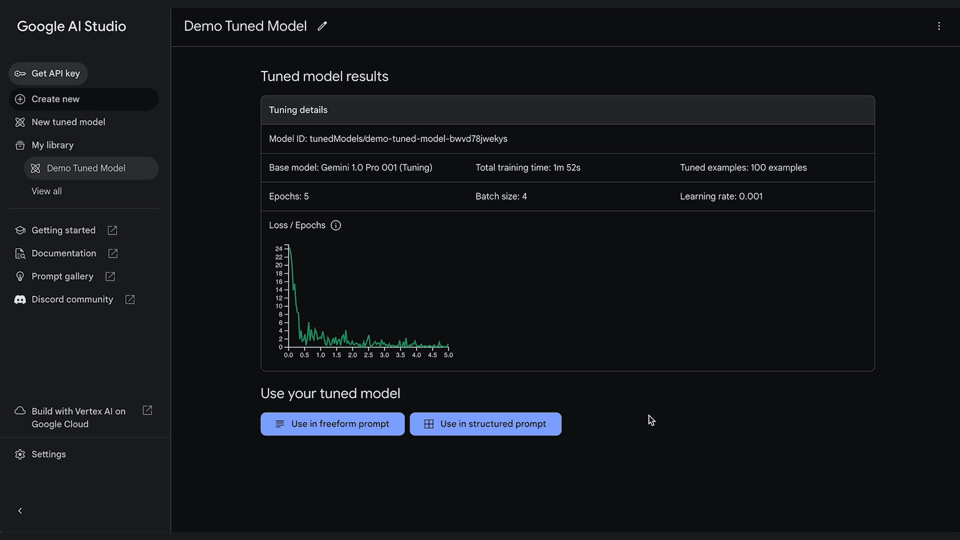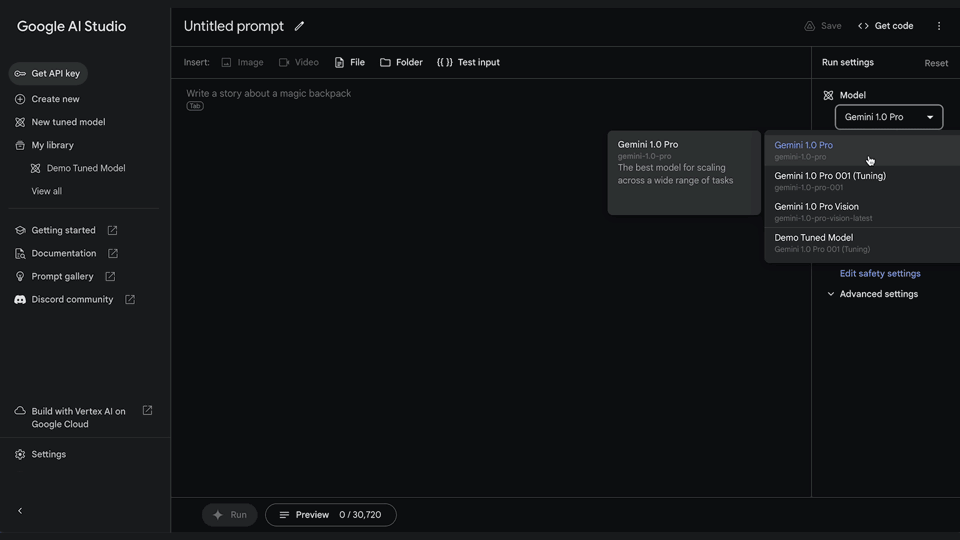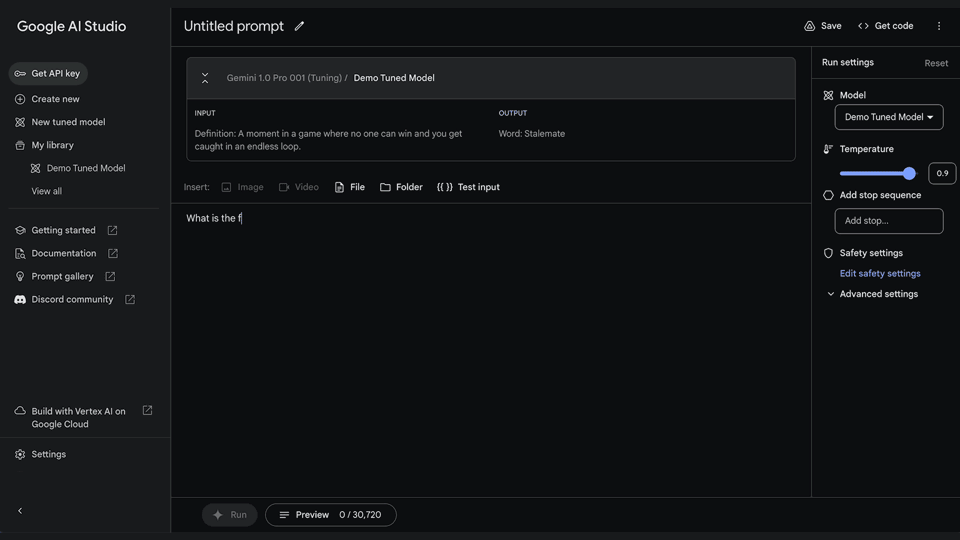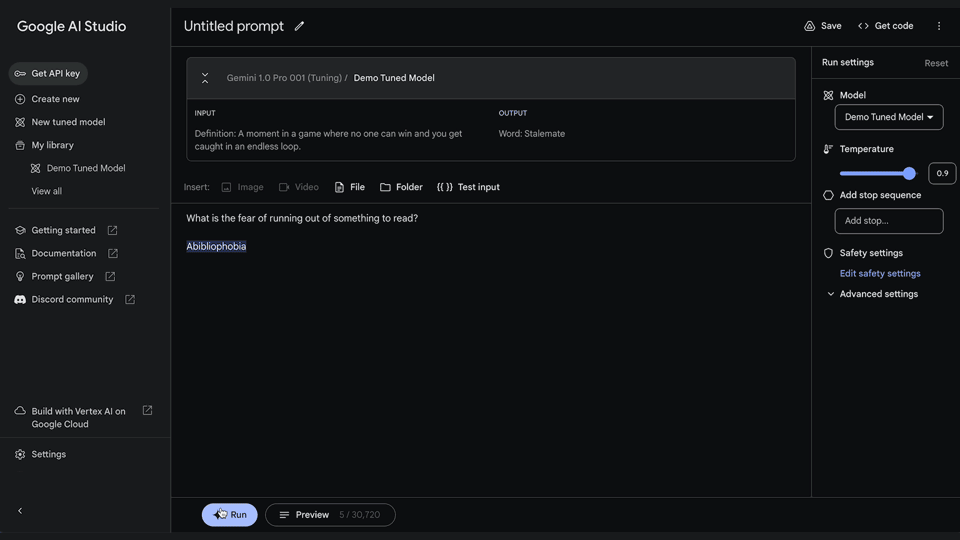
 Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations
Posted by Jeanine Banks – VP & General Manager, Developer X, and Head of Developer Relations
 Posted by Justyna Politanska-Pyszko – Program Manager, Google Developer Experts
Posted by Justyna Politanska-Pyszko – Program Manager, Google Developer Experts

 Posted by Aurash Mahbod – General Manager, Games on Google Play
Posted by Aurash Mahbod – General Manager, Games on Google Play
 Posted by Mark Sherwood – Senior Product Manager and Juhyun Lee – Staff Software Engineer
Posted by Mark Sherwood – Senior Product Manager and Juhyun Lee – Staff Software Engineer


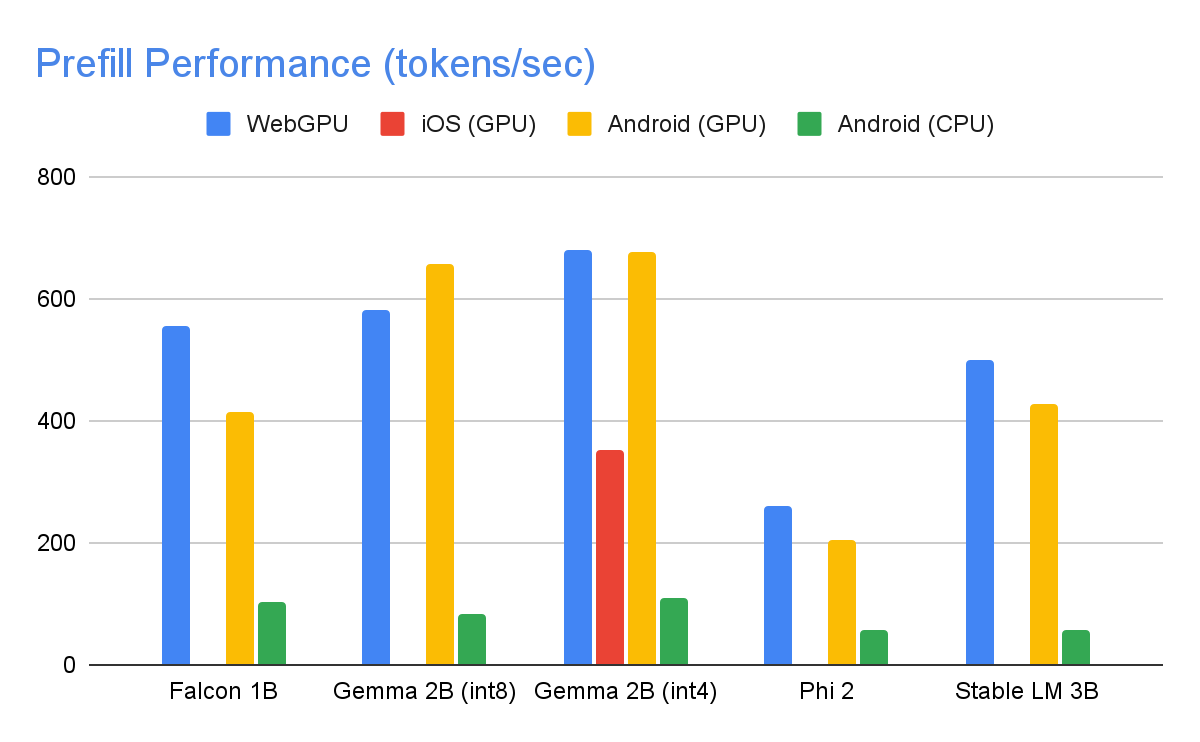



 Posted by
Posted by  Posted by Ali Satter – AI Lead, Roman Nurik – Design Lead, Kaushik Sathupadi and Jamal Carvalho – AI Engineers
Posted by Ali Satter – AI Lead, Roman Nurik – Design Lead, Kaushik Sathupadi and Jamal Carvalho – AI Engineers
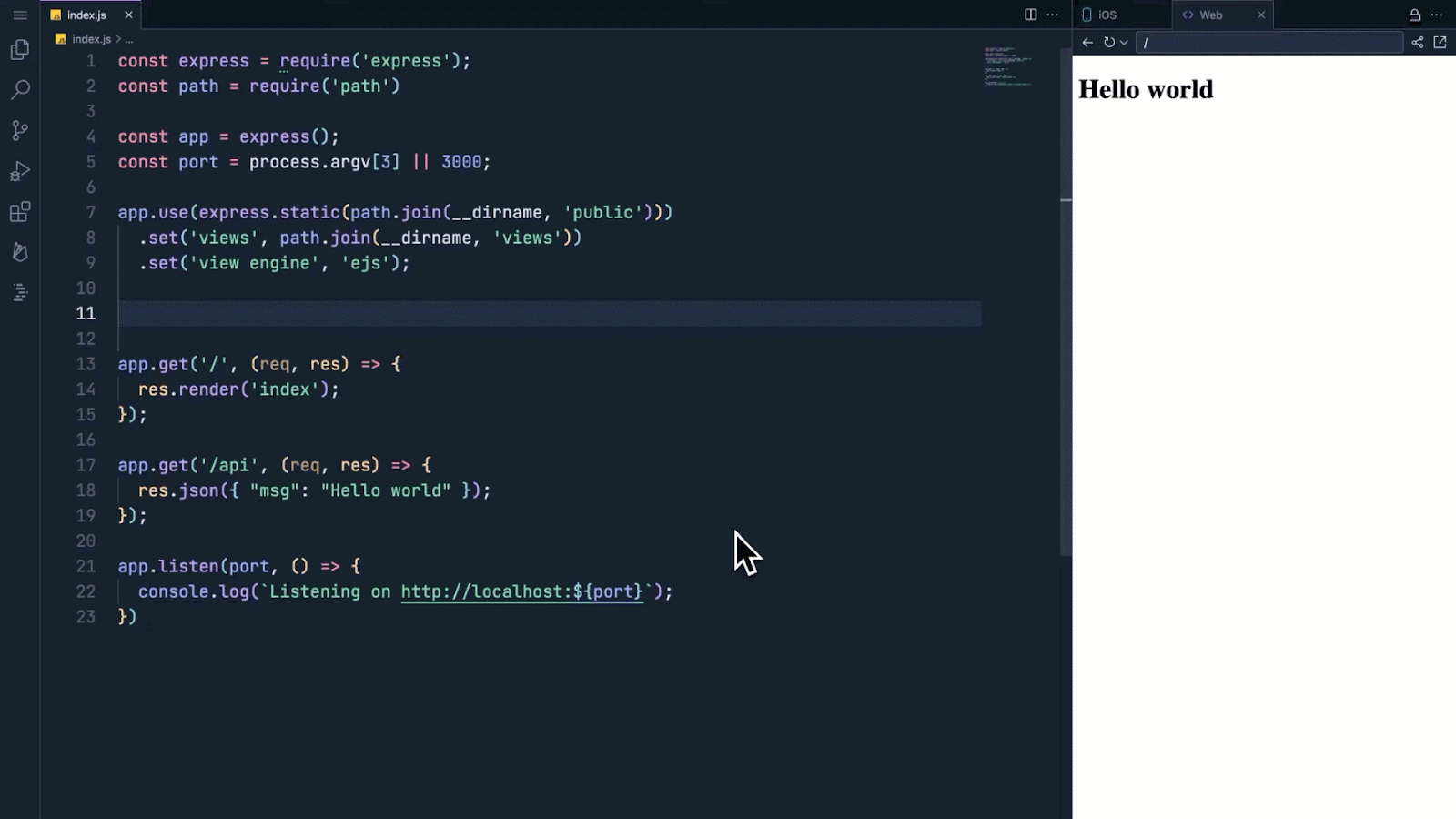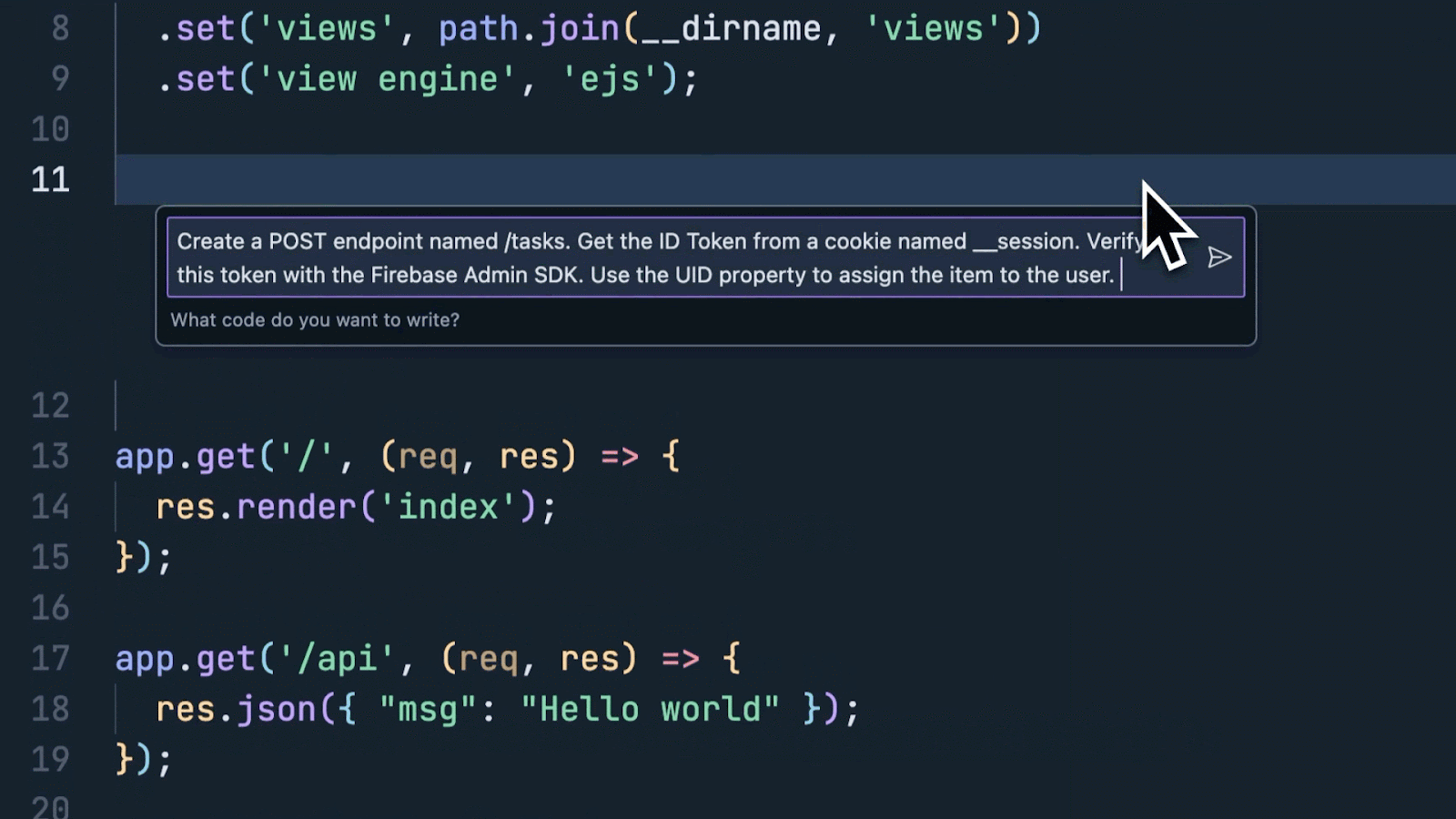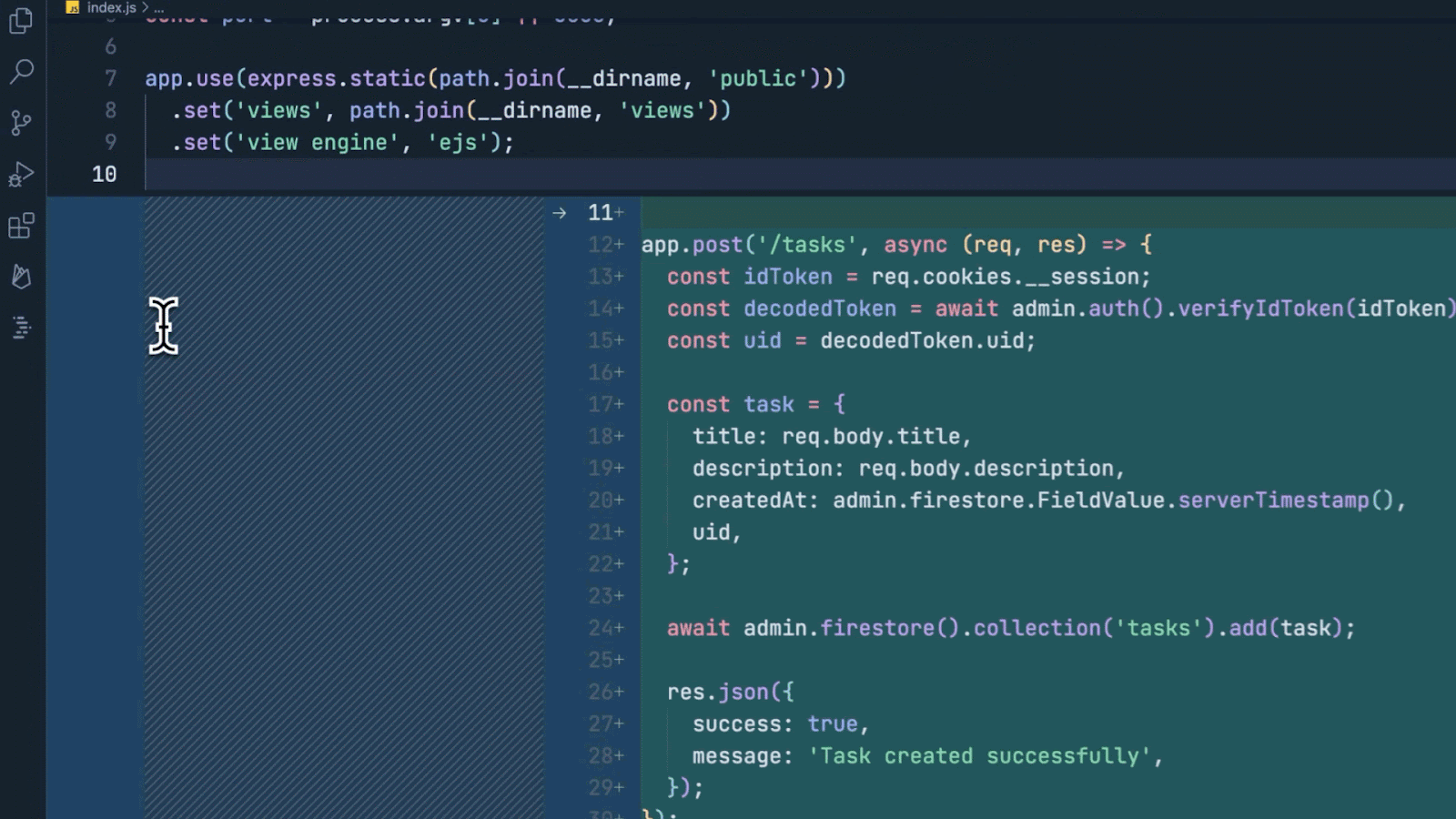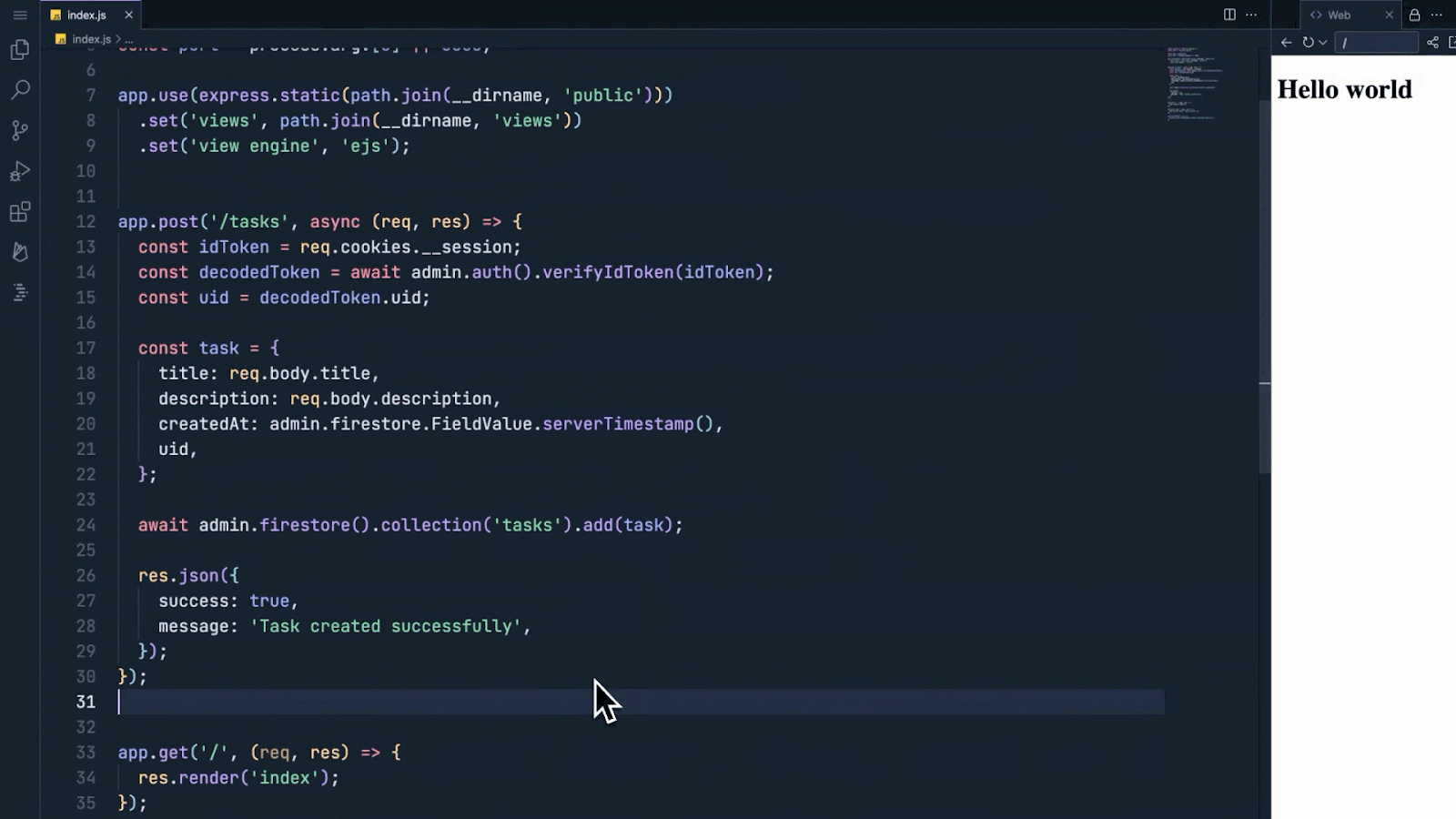
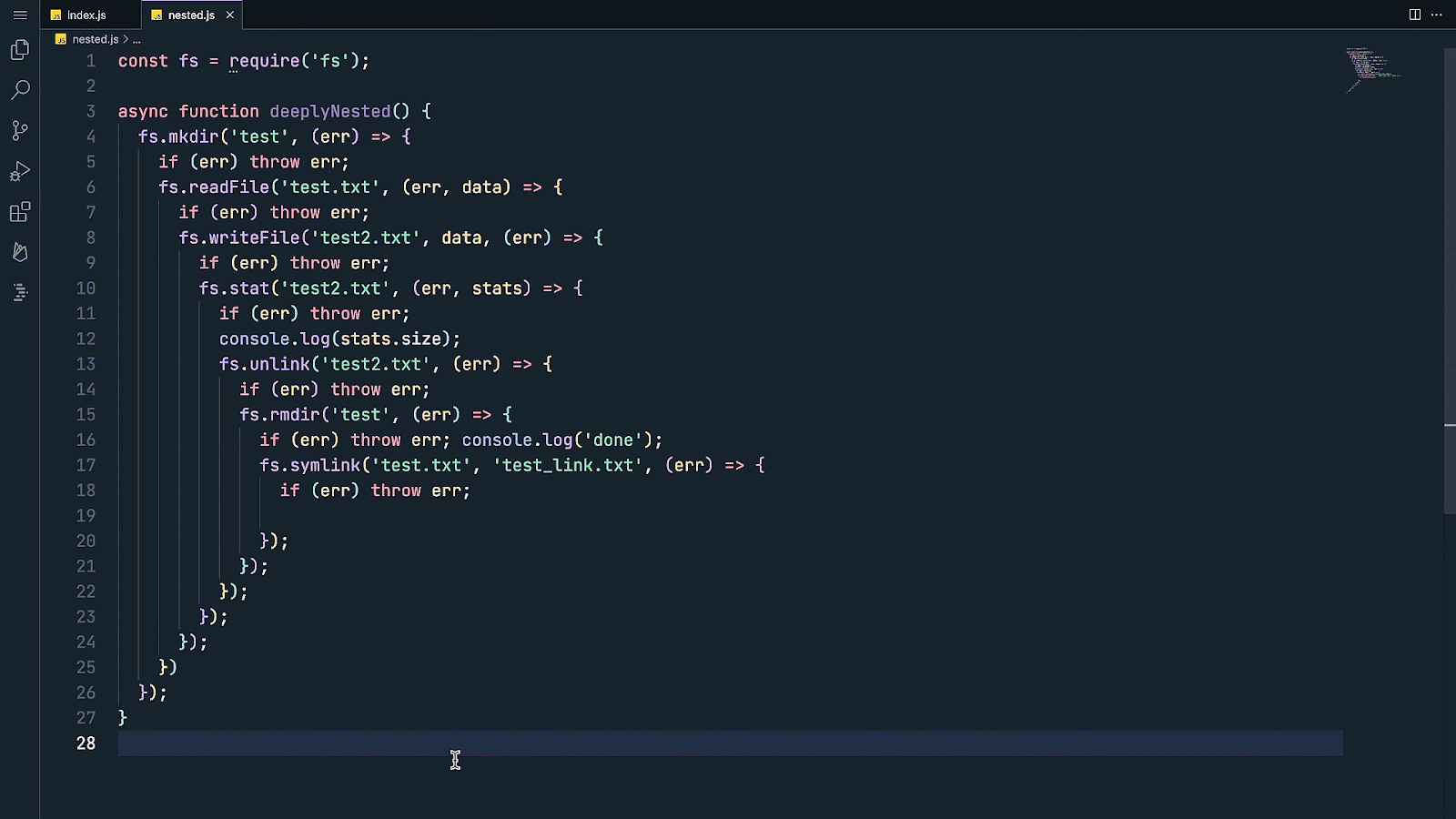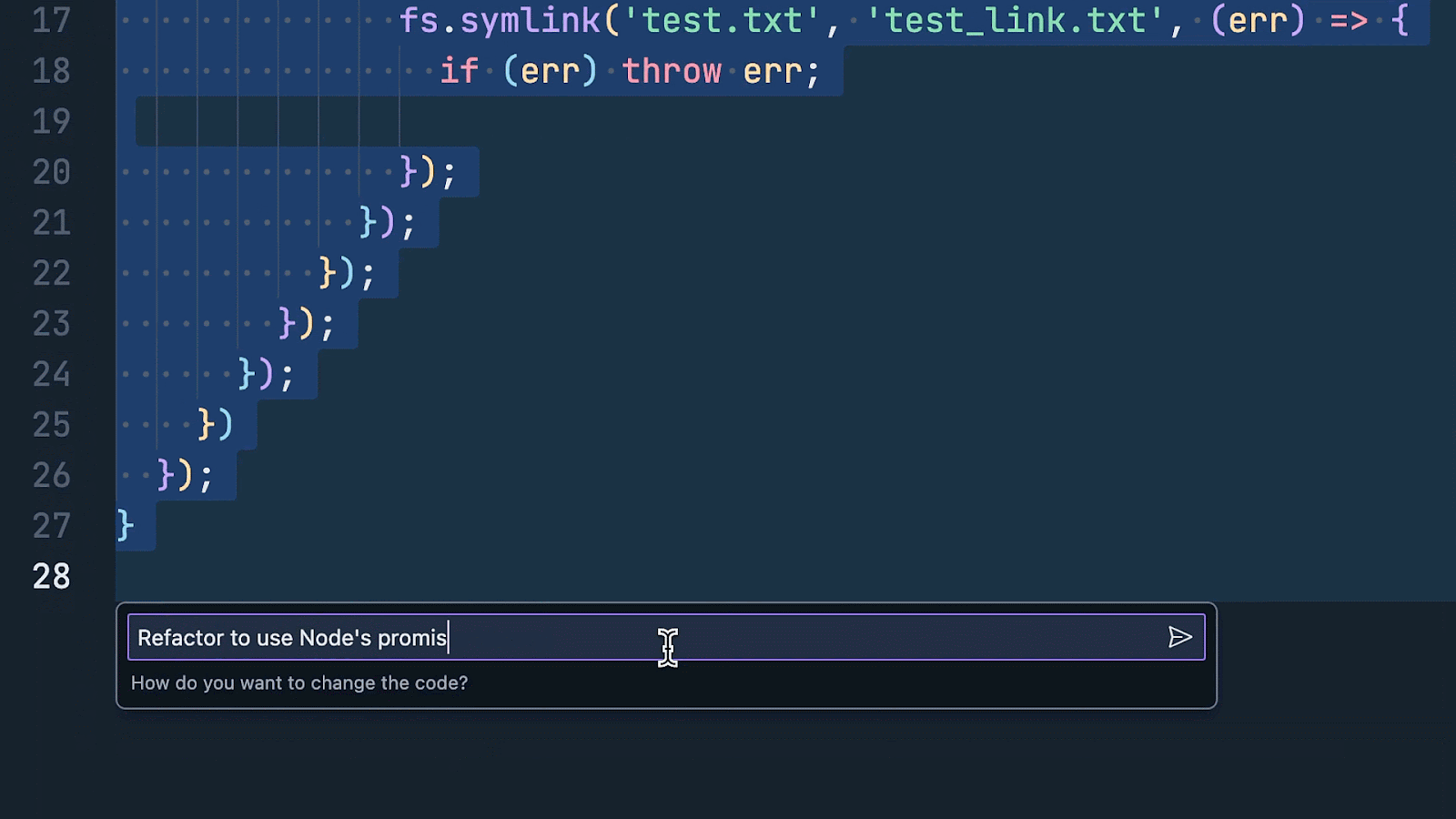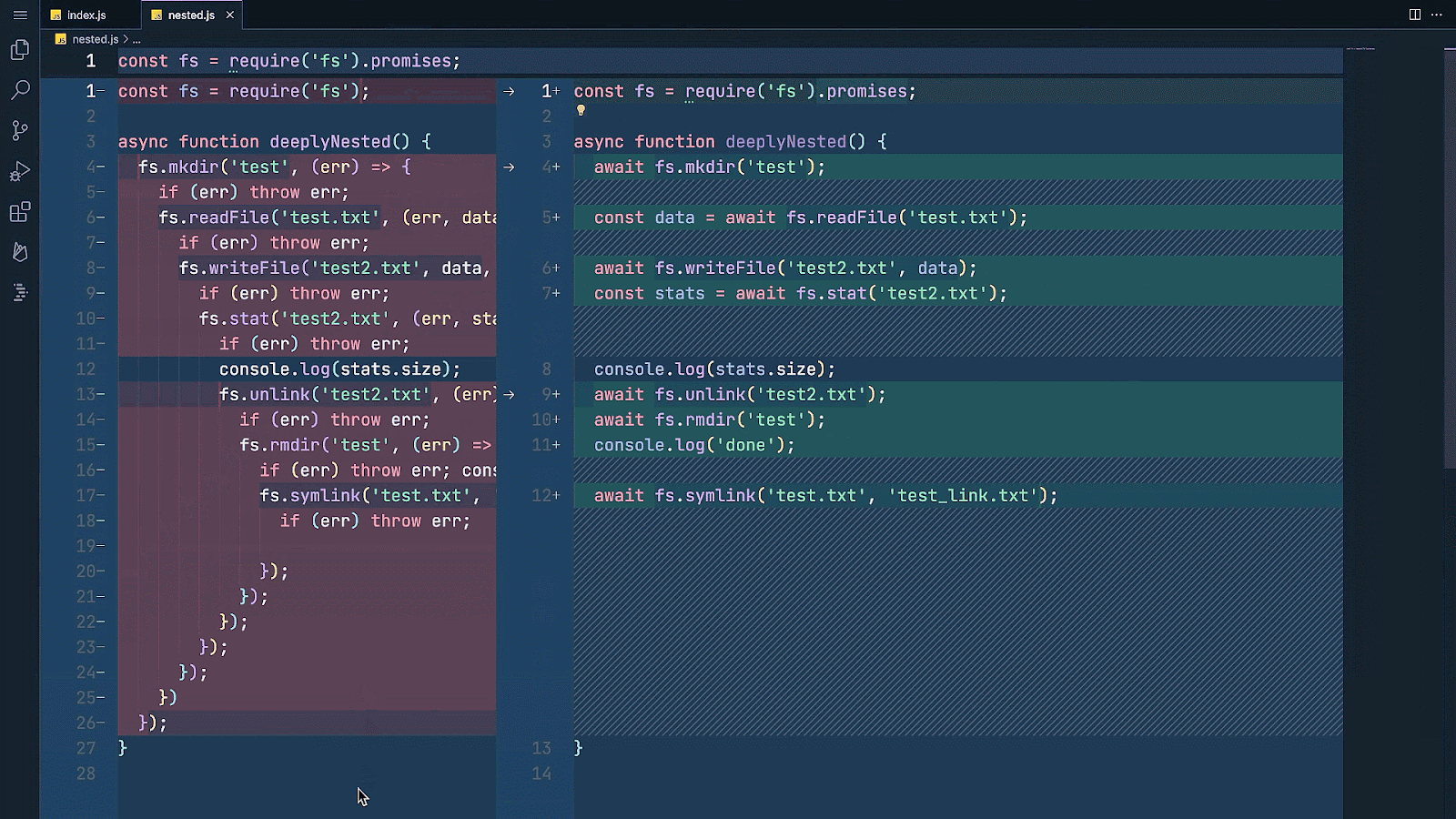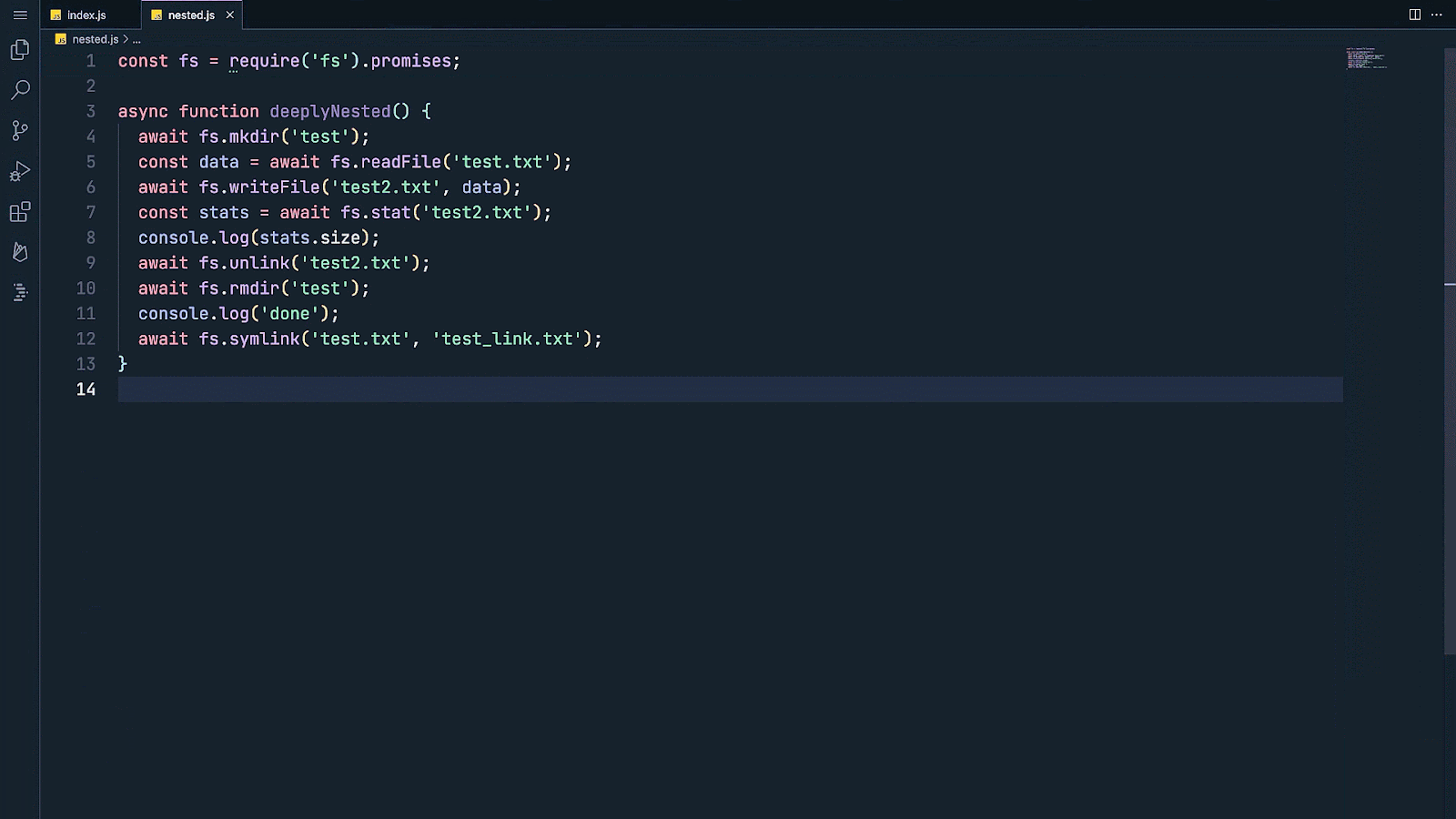

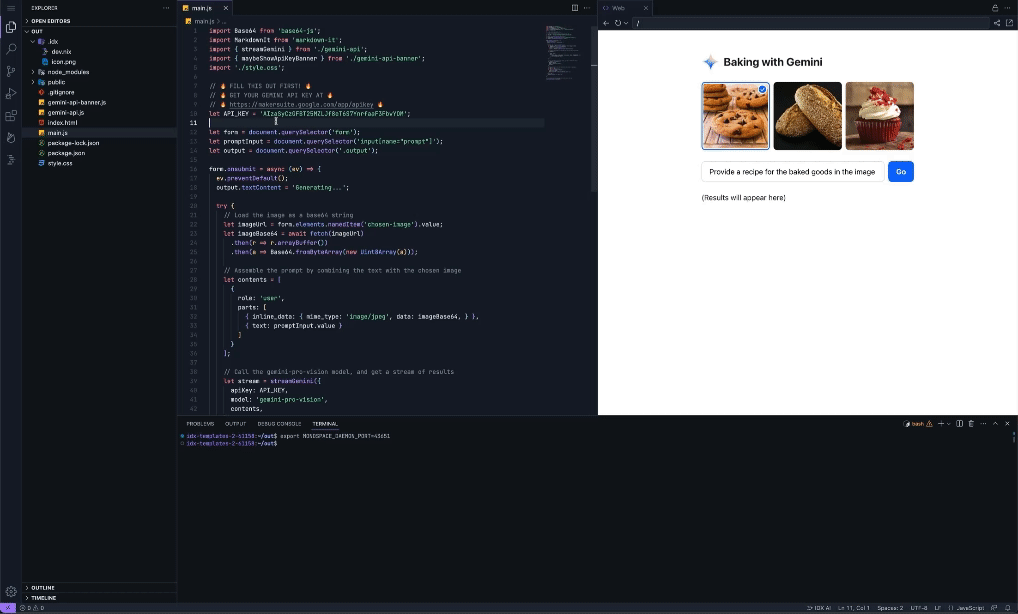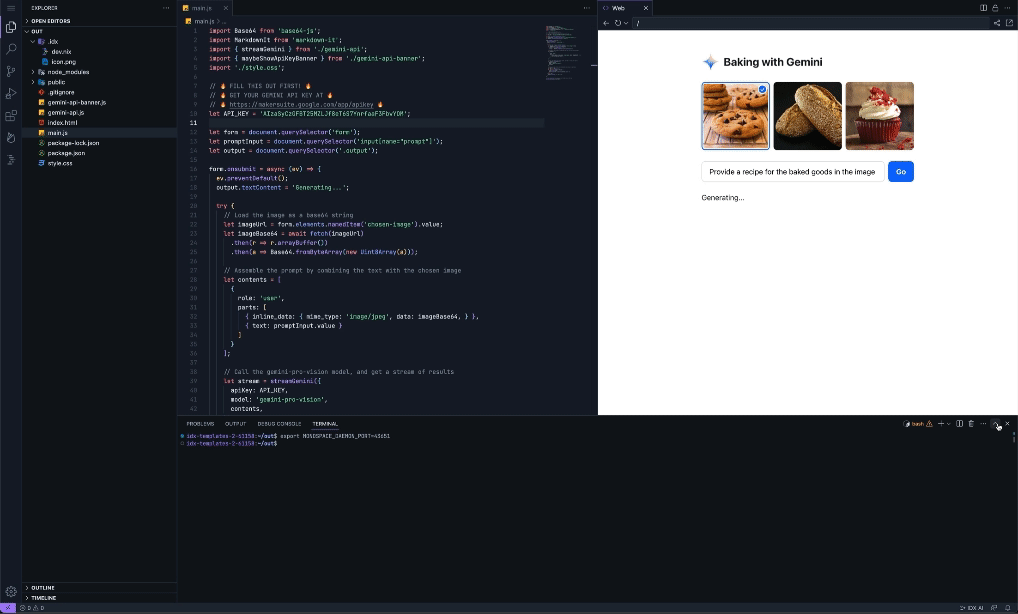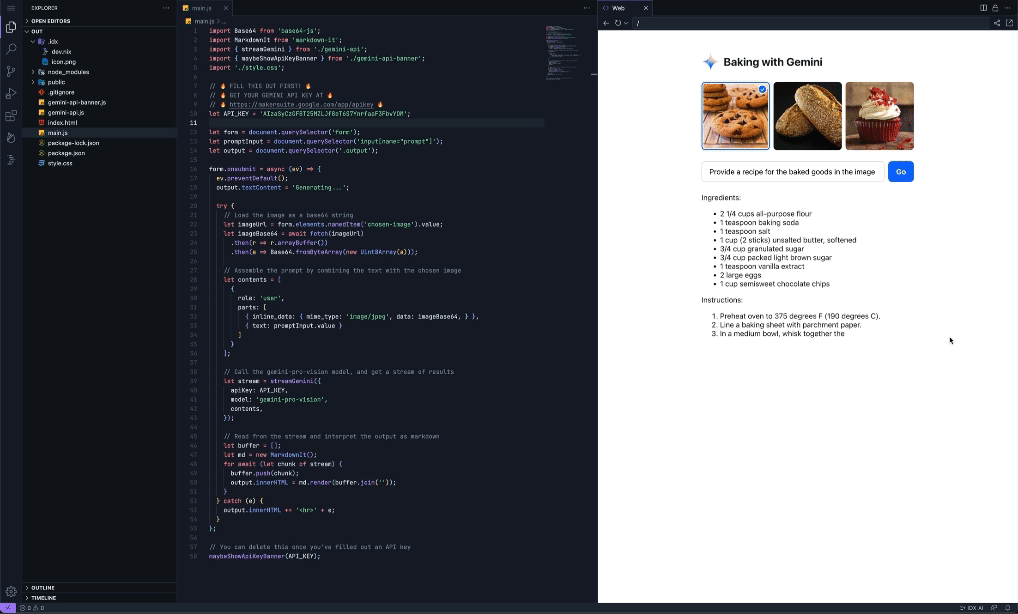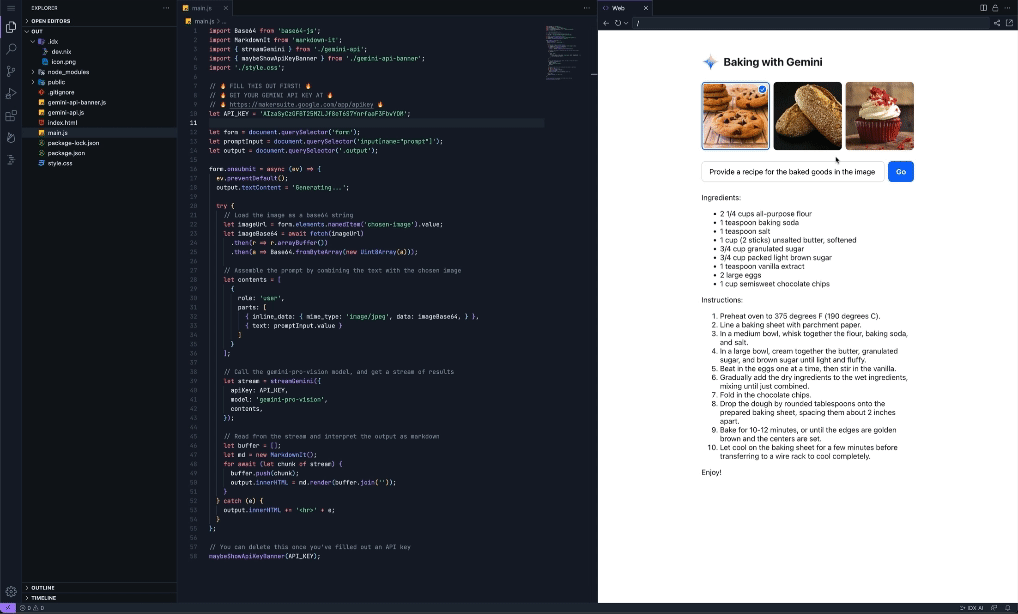
 Posted by Jaclyn Konzelmann and Wiktor Gworek – Google Labs
Posted by Jaclyn Konzelmann and Wiktor Gworek – Google Labs


 Posted by Dominik Mengelt– Developer Relations Engineer, Payments and Florin Modrea - Product Solutions Engineer, Google Pay
Posted by Dominik Mengelt– Developer Relations Engineer, Payments and Florin Modrea - Product Solutions Engineer, Google Pay


 Posted by Rachel Francois, Global Program Manager, Google Developer Student Clubs
Posted by Rachel Francois, Global Program Manager, Google Developer Student Clubs



 Posted by Gina Biernacki, Product Manager
Posted by Gina Biernacki, Product Manager

